January 27, 2023 · 45 min · Lilian Weng
自从我三年前关于 “Transformer家族” 的最后一篇文章以来,已经有许多新的 Transformer 架构改进被提出。在这里,我对2020年的帖子进行了大的重构和丰富——重新构建了章节的层次结构,并使用更多的近期论文改进了许多章节。版本 2.0 是旧版本的超集,长度大约是其两倍。
符号说明
| 符号 | 含义 |
|---|---|
| $d$ | 模型尺寸 / 隐藏状态维度 / 位置编码尺寸。 |
| $h$ | 多头注意力层中的头数。 |
| $L$ | 输入序列的段长度。 |
| $N$ | 模型中的注意力层总数;不考虑MoE。 |
| $\mathbf{X} \in \mathbb{R}^{L \times d}$ | 输入序列,其中每个元素都映射到一个形状为$d$的嵌入向量,与模型尺寸相同。 |
| $\mathbf{W}^k \in \mathbb{R}^{d \times d_k}$ | 键权重矩阵。 |
| $\mathbf{W}^q \in \mathbb{R}^{d \times d_k}$ | 查询权重矩阵。 |
| $\mathbf{W}^v \in \mathbb{R}^{d \times d_v}$ | 值权重矩阵。通常我们有$d_k = d_v = d$。 |
| $\mathbf{W}^k_i, \mathbf{W}^q_i \in \mathbb{R}^{d \times d_k/h}; \mathbf{W}^v_i \in \mathbb{R}^{d \times d_v/h}$ | 每个头部的权重矩阵。 |
| $\mathbf{W}^o \in \mathbb{R}^{d_v \times d}$ | 输出权重矩阵。 |
| $\mathbf{Q} = \mathbf{X}\mathbf{W}^q \in \mathbb{R}^{L \times d_k}$ | 查询嵌入输入。 |
| $\mathbf{K} = \mathbf{X}\mathbf{W}^k \in \mathbb{R}^{L \times d_k}$ | 键嵌入输入。 |
| $\mathbf{V} = \mathbf{X}\mathbf{W}^v \in \mathbb{R}^{L \times d_v}$ | 值嵌入输入。 |
| $\mathbf{q}_i, \mathbf{k}_i \in \mathbb{R}^{d_k}, \mathbf{v}_i \in \mathbb{R}^{d_v}$ | 在查询、键、值矩阵中的行向量,$\mathbf{Q}$, $\mathbf{K}$ 和 $\mathbf{V}$。 |
| $S_i$ | 第$i$个查询$\mathbf{q}_i$需要注意的键位置的集合。 |
| $\mathbf{A} \in \mathbb{R}^{L \times L}$ | 输入序列长度为$L$与其自身之间的自注意力矩阵。$\mathbf{A} = \text{softmax}(\mathbf{Q}\mathbf{K}^\top / \sqrt{d_k})$。 |
| $a_{ij} \in \mathbf{A}$ | 查询$\mathbf{q}_i$与键$\mathbf{k}_j$之间的标量注意力得分。 |
| $\mathbf{P} \in \mathbb{R}^{L \times d}$ | 位置编码矩阵,其中第$i$行$\mathbf{p}_i$是输入$\mathbf{x}_i$的位置编码。 |
Transformer 基础
Transformer(为了与其他增强版本区分,这里将其称为“原始 Transformer”;Vaswani等人,2017 )模型具有编码器-解码器架构,这在许多NMT 模型中都很常见。后来简化的Transformer在语言建模任务中表现出色,如仅有编码器的 BERT 或仅有解码器的 GPT 。
注意力机制与自注意力机制
注意力机制 是神经网络中的一种机制,模型可以通过选择性地关注给定的数据集来学习并做出预测。注意力的量由学习到的权重量化,因此输出通常形成为加权平均值。
自注意力机制 是一种注意力机制,模型使用同一数据样本的其他部分关于同一样本的观察来为数据样本的一部分做出预测。从概念上看,它与非局部均值 感觉相当相似。还要注意,自注意力是排列不变的;换句话说,它是一个集合上的操作。
注意力/自注意力有各种形式,Transformer(Vaswani等,2017 )依赖于_缩放点积注意力_:给定一个查询矩阵$\mathbf{Q}$,一个键矩阵$\mathbf{K}$和一个值矩阵$\mathbf{V}$,输出是值向量的加权总和,其中每个值槽的权重由查询与相应键的点积确定:
$$ \text{attn}(\mathbf{Q}, \mathbf{K}, \mathbf{V}) = \text{softmax}(\frac{\mathbf{Q} {\mathbf{K}}^\top}{\sqrt{d_k}})\mathbf{V} $$
对于查询和键向量$\mathbf{q}_i, \mathbf{k}_j \in \mathbb{R}^d$(查询和键矩阵中的行向量),我们有一个标量分数:
$$ a_{ij} = \text{softmax}(\frac{\mathbf{q}_i {\mathbf{k}_j}^\top}{\sqrt{d_k}}) = \frac{\exp(\mathbf{q}_i {\mathbf{k}_j}^\top)}{ \sqrt{d_k} \sum_{r \in \mathcal{S}_i} \exp(\mathbf{q}_i {\mathbf{k}_r}^\top) } $$
其中$\mathcal{S}_i$是$i$-th查询要关注的键位置的集合。
如果感兴趣,可以参阅我早期的关于其他类型注意力的文章 。
多头自注意力
多头自注意力 模块是 Transformer 的关键组件。多头机制将输入分割为较小的块,然后并行地计算每个子空间上的缩放点积注意力。独立的注意力输出只是简单地连接并线性地转换成预期的维度。
$$ \begin{aligned} \text{MultiHeadAttn}(\mathbf{X}_q, \mathbf{X}_k, \mathbf{X}_v) &= [\text{head}_1; \dots; \text{head}_h] \mathbf{W}^o \\ \text{where head}_i &= \text{Attention}(\mathbf{X}_q\mathbf{W}^q_i, \mathbf{X}_k\mathbf{W}^k_i, \mathbf{X}_v\mathbf{W}^v_i) \end{aligned} $$
其中$[.;.]$是连接操作。$\mathbf{W}^q_i, \mathbf{W}^k_i \in \mathbb{R}^{d \times d_k/h}, \mathbf{W}^v_i \in \mathbb{R}^{d \times d_v/h}$是权重矩阵,用于将大小为$L \times d$的输入嵌入映射到查询、键和值矩阵。而$\mathbf{W}^o \in \mathbb{R}^{d_v \times d}$是输出线性变换。所有的权重在训练过程中都应该被学习。
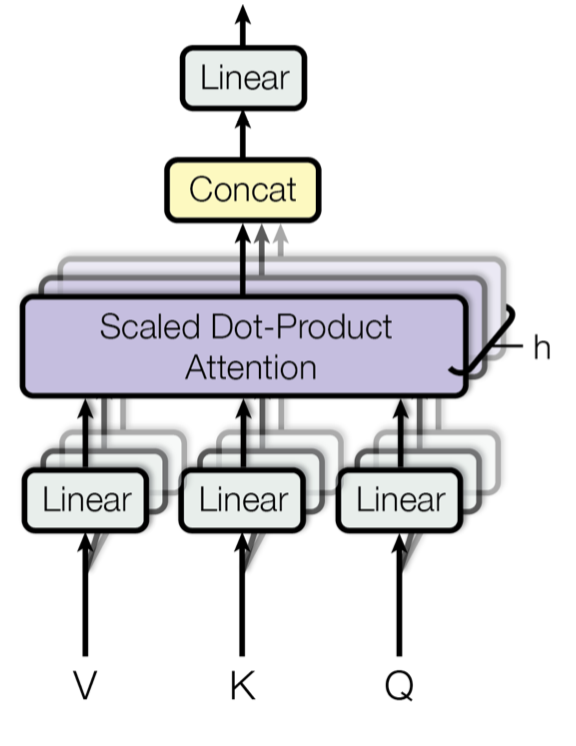
图 1. 多头缩放点积注意力机制的示意图。(图片来源:Vaswani, 等,2017 中的图 2)
编码器-解码器结构
编码器生成一个基于注意力的表示,这种表示能够从大的上下文中定位特定的信息片段。它由 6 个身份模块组成,每个模块包含两个子模块,一个是_多头自注意力_层,另一个是_逐点_全连接前馈网络。逐点意味着对序列中的每个元素应用相同的线性变换(使用相同的权重)。这也可以被视为具有 1 的滤波器大小的卷积层。每个子模块都有一个残差连接和层归一化。所有的子模块都输出相同维度的数据 $d$。
Transformer 解码器的功能是从编码表示中检索信息。其结构与编码器非常相似,不过解码器在每个相同的重复模块中包含两个多头注意力子模块,而不是一个。第一个多头注意力子模块是_掩码的_,用于防止位置注意到未来的信息。
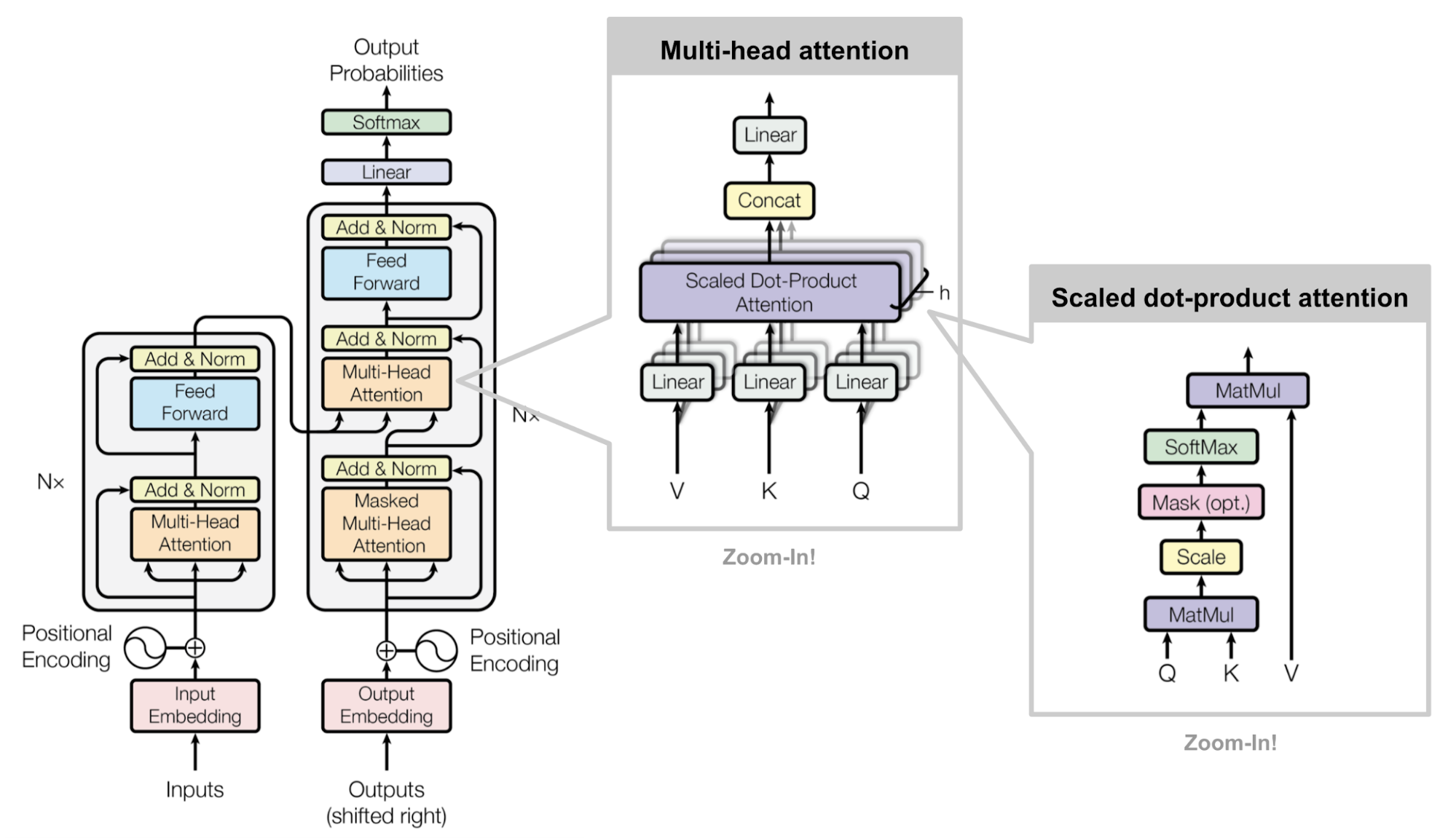
图 2. 原始Transformer模型的结构。(图片来源:图 17 )
位置编码
因为自注意力操作是排列不变的,所以使用合适的位置编码为模型提供_顺序信息_是很重要的。位置编码 $\mathbf{P} \in \mathbb{R}^{L \times d}$ 与输入嵌入的维度相同,所以可以直接加在输入上。原始的 Transformer 考虑了两种编码:
正弦位置编码
给定标记位置 $i=1,\dots,L$ 和维度 $\delta=1,\dots,d$ ,正弦位置编码定义如下:
$$ \text{PE}(i,\delta) = \begin{cases} \sin(\frac{i}{10000^{2\delta’/d}}) & \text{if } \delta = 2\delta’\\ \cos(\frac{i}{10000^{2\delta’/d}}) & \text{if } \delta = 2\delta’ + 1\\ \end{cases} $$
这样,位置编码的每个维度都对应于不同维度的不同波长的正弦曲线,从 $2\pi$ 到 $10000 \cdot 2\pi$。
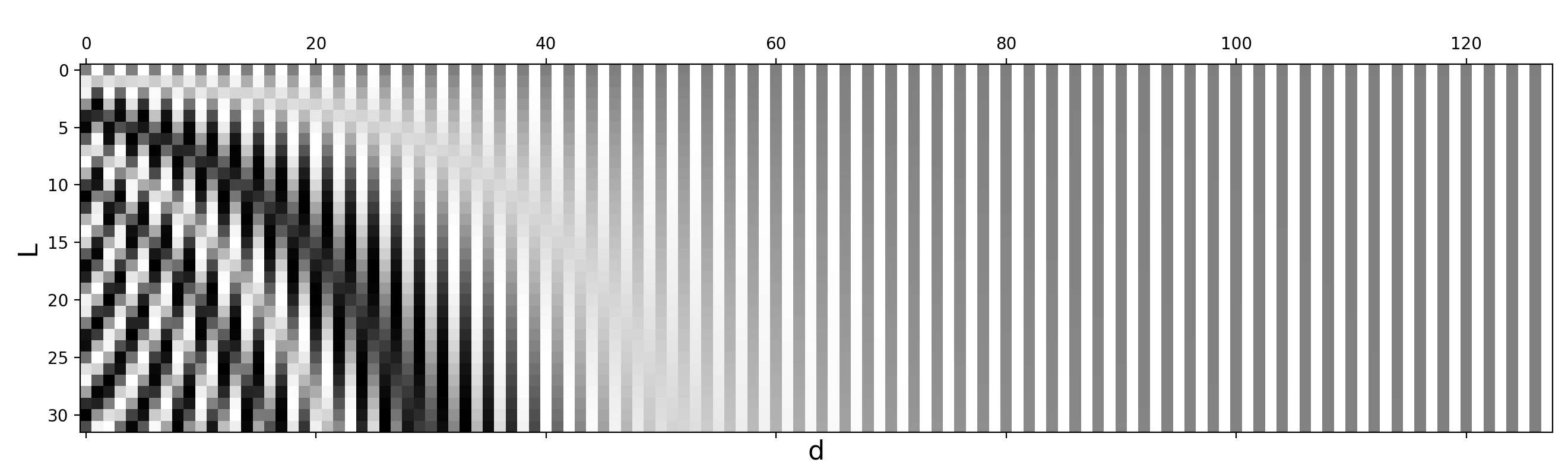
图 3. 具有 $L=32$ 和 $d=128$ 的正弦位置编码。值在 -1(黑色)和 1(白色)之间,0 值为灰色。
学习位置编码
学习位置编码为每个元素分配一个_学习_的列向量,该向量编码其绝对位置(Gehring等人,2017 ),并且这种编码可以每层都有不同的学习方式(Al-Rfou等人,2018 )。
相对位置编码
Shaw et al. (2018) 在 $\mathbf{W}^k$ 和 $\mathbf{W}^v$ 中加入了相对位置信息。最大的相对位置被限制为最大的绝对值$k$,并且这种裁剪操作使得模型能够泛化到未见过的序列长度。因此,考虑 $2k + 1$ 个唯一的边标签,并将 $\mathbf{P}^k, \mathbf{P}^v \in \mathbb{R}^{2k+1}$ 定义为可学习的相对位置表示。
$$ A_{ij}^k = P^k_{\text{clip}(j - i, k)} \quad A_{ij}^v = P^v_{\text{clip}(j - i, k)} \quad \text{其中}\text{clip}(x, k) = \text{clip}(x, -k, k) $$
Transformer-XL (Dai et al., 2019 ) 提出了一种基于重新参数化键和查询的点积的相对位置编码方法。为了在各个段中连贯地保持位置信息,Transformer-XL编码了相对位置,因为知道偏移位置足够进行良好的预测,例如 $i-j$,在一个键向量 $\mathbf{k}_{\tau, j}$ 和它的查询 $\mathbf{q}_{\tau, i}$ 之间。
如果省略标量 $1/\sqrt{d_k}$ 和softmax中的归一化项,但包括位置编码,我们可以写出位置 $i$ 的查询和位置 $j$ 的键之间的注意力得分为:
$$ \begin{aligned} a_{ij} &= \mathbf{q}_i {\mathbf{k}_j}^\top = (\mathbf{x}_i + \mathbf{p}_i)\mathbf{W}^q ((\mathbf{x}_j + \mathbf{p}_j)\mathbf{W}^k)^\top \\ &= \mathbf{x}_i\mathbf{W}^q {\mathbf{W}^k}^\top\mathbf{x}_j^\top + \mathbf{x}_i\mathbf{W}^q {\mathbf{W}^k}^\top\mathbf{p}_j^\top + \mathbf{p}_i\mathbf{W}^q {\mathbf{W}^k}^\top\mathbf{x}_j^\top + \mathbf{p}_i\mathbf{W}^q {\mathbf{W}^k}^\top\mathbf{p}_j^\top \end{aligned} $$
Transformer-XL 重新参数化了上述四个术语如下:
$$ a_{ij}^\text{rel} = \underbrace{ \mathbf{x}_i\mathbf{W}^q \color{blue}{ {\mathbf{W}_E^k}^\top } \mathbf{x}_j^\top }_{\text{content-based addressing}} + \underbrace{ \mathbf{x}_i\mathbf{W}^q \color{blue}{ {\mathbf{W}_R^k}^\top } \color{green}{\mathbf{r}{(i-j)}^\top} }_{\text{context-dependent positional bias}} + \underbrace{ \color{red}{\mathbf{u}} \color{blue}{ {\mathbf{W}_E^k}^\top } \mathbf{x}_j^\top }_{\text{全局内容偏见}} + \underbrace{ \color{red}{\mathbf{v}} \color{blue}{ {\mathbf{W}_R^k}^\top } \color{green}{\mathbf{r}_{(i-j)}^\top} }_{\text{global pisitional bias}} $$
- 用相对位置编码 $\mathbf{r}_{i-j} \in \mathbf{R}^{d}$ 替换 $\mathbf{p}_j$;
- 用两个可训练参数 $\mathbf{u}$(用于内容)和 $\mathbf{v}$(用于位置)在两个不同的术语中替换 $\mathbf{p}_i\mathbf{W}^q$;
- 将 $\mathbf{W}^k$ 分割为两个矩阵,$\mathbf{W}^k_E$ 用于内容信息和 $\mathbf{W}^k_R$ 用于位置信息。
旋转位置嵌入
旋转位置嵌入(RoPE; Su等,2021年 )使用旋转矩阵 编码绝对位置,并将其与每个注意力层的键和值矩阵相乘,从而在每一层注入相对位置信息。
当将相对位置信息编码到第$i$个键和第$j$个查询的内积中时,我们希望将该函数表述为内积仅与相对位置$i-j$有关。旋转位置嵌入(RoPE)利用欧几里得空间中的旋转操作,并将相对位置嵌入简化为按与其位置索引成正比的角度旋转特征矩阵。
给定一个向量$\mathbf{z}$,如果我们想要逆时针旋转它$\theta$,我们可以通过旋转矩阵将其相乘得到$R\mathbf{z}$,其中旋转矩阵$R$定义为:
$$ R = \begin{bmatrix} \cos\theta & -\sin\theta \\ \sin\theta & \cos\theta \end{bmatrix} $$
当推广到更高维空间时,RoPE将$d$维空间分为$d/2$个子空间,并为位置 $i$ 的令牌构造大小为 $d \times d$ 的旋转矩阵 $R$ :
$$ R^d_{\Theta, i} = \begin{bmatrix} \cos i\theta_1 & -\sin i\theta_1 & 0 & 0 & \dots & 0 & 0 \\ \sin i\theta_1 & \cos i\theta_1 & 0 & 0 & \dots & 0 & 0 \\ 0 & 0 & \cos i\theta_2 & -\sin i\theta_2 & \dots & 0 & 0 \\ 0 & 0 & \sin i\theta_1 & \cos i\theta_1 & \dots & 0 & 0 \\ \vdots & \vdots & \vdots & \vdots & \ddots & \vdots & \vdots \\ 0 & 0 & 0 & 0 & \dots & \cos i\theta_{d/2} & -\sin i\theta_{d/2} \\ 0 & 0 & 0 & 0 & \dots & \sin i\theta_{d/2} & \cos i\theta_{d/2} \\ \end{bmatrix} $$
在该论文中,我们有$\Theta = {\theta_i = 10000^{-2(i−1)/d}, i \in [1, 2, …, d/2]}$。注意,这实际上等同于正弦位置编码,但表述为旋转矩阵。
然后,键和查询矩阵都通过与这个旋转矩阵相乘来融入位置信息:
$$ \begin{aligned} & \mathbf{q}_i^\top \mathbf{k}_j = (R^d_{\Theta, i} \mathbf{W}^q\mathbf{x}_i)^\top (R^d_{\Theta, j} \mathbf{W}^k\mathbf{x}_j) = \mathbf{x}_i^\top\mathbf{W}^q R^d_{\Theta, j-i}\mathbf{W}^k\mathbf{x}_j \\ & \text{ 其中 } R^d_{\Theta, j-i} = (R^d_{\Theta, i})^\top R^d_{\Theta, j} \end{aligned} $$
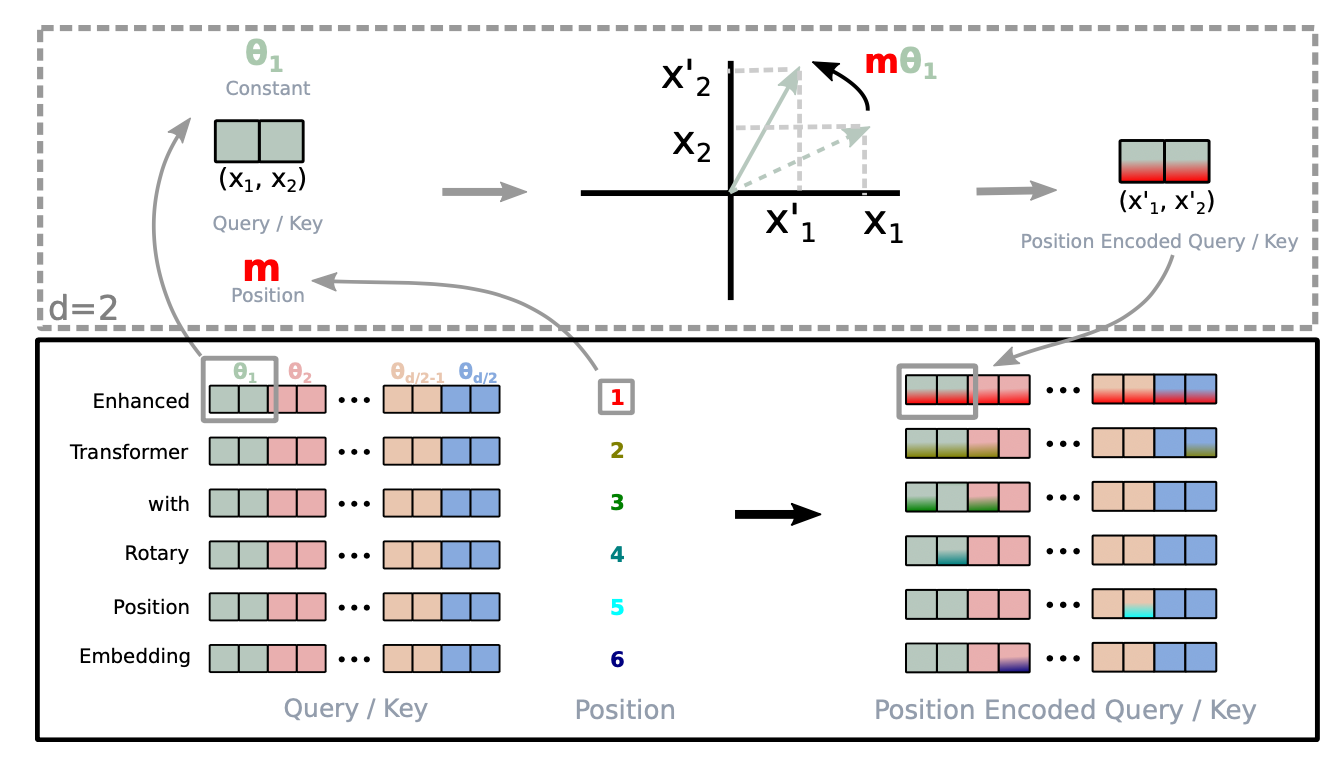
图 4. 旋转位置嵌入如何实现的直观插图。(图片来源:Su等,2021 )
更长上下文
Transformer 模型在推理时的输入序列长度受到其训练时使用的上下文长度的上限限制。简单地增加上下文长度会导致时间 ($\mathcal{O}(L^2d)$) 和内存 ($\mathcal{O}(L^2)$) 的消耗增加,并且可能因硬件限制而不被支持。
本节介绍了 Transformer 架构的几种改进,以在推理时更好地支持长上下文;例如使用额外的内存,为更好的上下文外推设计或循环机制。
上下文记忆
原始的 Transformer 有一个固定且有限的注意力范围。在每次更新步骤中,模型只能关注同一段中的其他元素,且不允许信息流过不同的固定长度段。这种 上下文分段 导致了几个问题:
- 模型无法捕捉非常长期的依赖关系。
- 在每段的前几个token上进行预测时,由于没有或者只有很薄弱的上下文,使得预测变得困难。
- 评估成本高昂。每当段向右移动一个位置时,新的段都需要从头开始重新处理,尽管有很多重叠的token。
Transformer-XL (Dai et al., 2019 ; “XL”表示“超长”) 修改了架构,以使用额外的内存在段之间重用隐藏状态。通过持续使用先前段的隐藏状态,模型引入了段之间的循环连接。
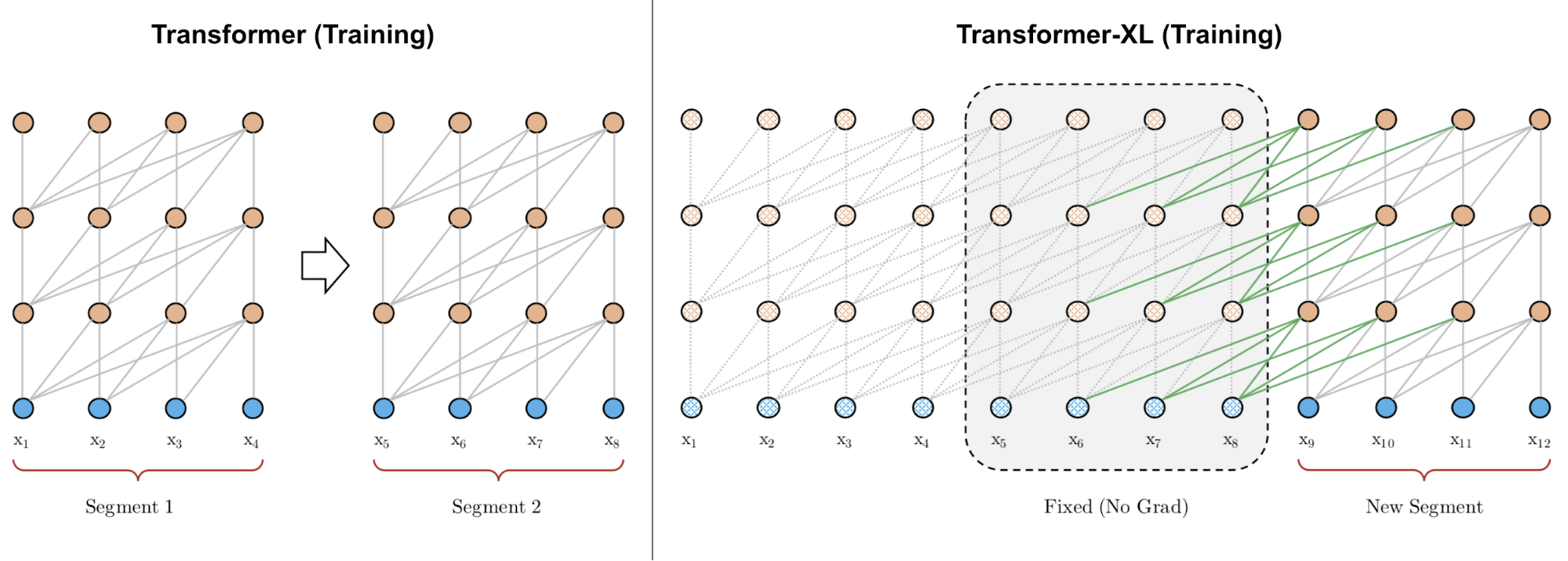
图 5. 与段长度为 4 的原始 Transformer 的训练阶段相比的 Transformer-XL。 (图片来源:Dai et al., 2019 中的图 2 左侧部分)。
我们将模型中第 $ (\tau + 1) $ 个段的第 $n$ 层的隐藏状态标记为 $\mathbf{h}_{\tau+1}^{(n)} \in \mathbb{R}^{L \times d}$。除了同一段的最后一层的隐藏状态 $ \mathbf{h}_{\tau+1}^{(n-1)} $ 外,它还取决于前一段的同一层的隐藏状态 $\mathbf{h}_{\tau}^{(n)}$。通过合并来自先前隐藏状态的信息,模型可以将注意力范围在过去的多个段中延长得更长。
$$ \begin{aligned} \color{red}{\widetilde{\mathbf{h}}_{\tau+1}^{(n-1)}} &= [\text{stop-gradient}(\mathbf{h}_{\tau}^{(n-1)}) \circ \mathbf{h}_{\tau+1}^{(n-1)}] \\ \mathbf{Q}_{\tau+1}^{(n)} &= \mathbf{h}_{\tau+1}^{(n-1)}\mathbf{W}^q \\ \mathbf{K}_{\tau+1}^{(n)} &= \color{red}{\widetilde{\mathbf{h}}_{\tau+1}^{(n-1)}} \mathbf{W}^k \\ \mathbf{V}_{\tau+1}^{(n)} &= \color{red}{\widetilde{\mathbf{h}}_{\tau+1}^{(n-1)}} \mathbf{W}^v \\ \mathbf{h}_{\tau+1}^{(n)} &= \text{transformer-layer}(\mathbf{Q}_{\tau+1}^{(n)}, \mathbf{K}_{\tau+1}^{(n)}, \mathbf{V}_{\tau+1}^{(n)}) \end{aligned} $$
注意,键和值都依赖于扩展的隐藏状态,而查询仅使用当前步骤的隐藏状态。连接操作 $[. \circ .]$ 沿着序列长度维度进行。并且 Transformer-XL 需要使用 相对位置编码 ,因为如果我们编码绝对位置,先前和当前的段将被分配相同的编码,这是不希望的。
压缩 Transformer (Rae et al. 2019 ) 通过压缩过去的记忆来扩展 Transformer-XL,以支持更长的序列。它明确地为每一层添加了大小为 $m_m$ 的 记忆 插槽,用于存储此层的过去的激活,以保存长上下文。当一些过去的激活变得足够旧时,它们被压缩并保存在每层大小为 $m_{cm}$ 的额外的 压缩记忆 中。
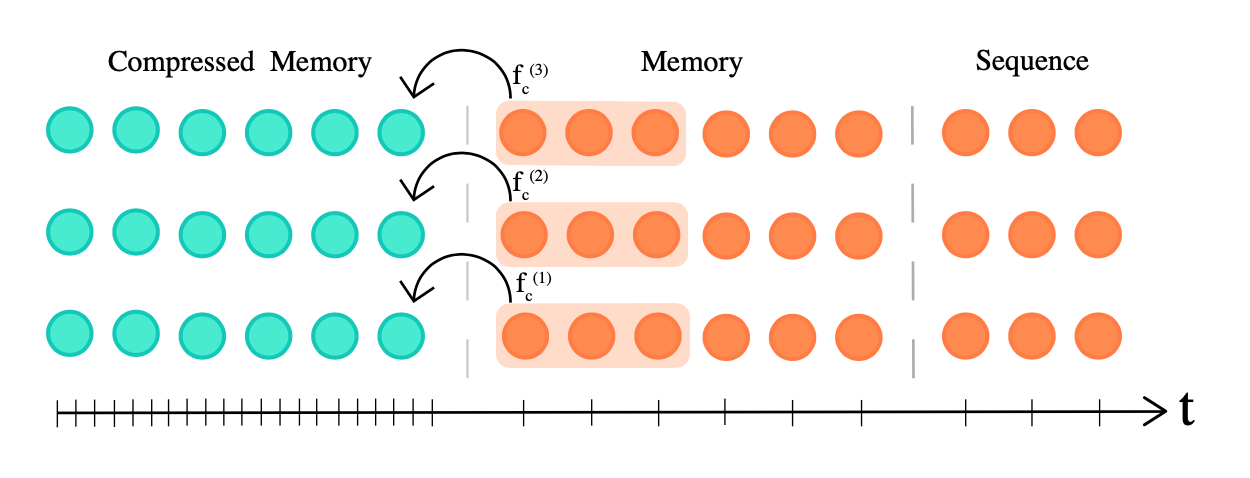
图 6. 压缩 transformer 维护了两种类型的记忆插槽,记忆和压缩记忆,以支持长上下文。 (图片来源:Rae et al. 2019 )。
记忆和压缩记忆都是 FIFO 队列。给定模型上下文长度 $L$,压缩函数的压缩率为 $c$ 定义为 $f_c: \mathbb{R}^{L \times d} \to \mathbb{R}^{[\frac{L}{c}] \times d}$,将 $L$ 个最旧的激活映射到 $[\frac{L}{c}]$ 压缩内存元素。有多种压缩函数选择:
- 核和步长大小为 $c$ 的最大/平均池化;
- 核和步长大小为 $c$ 的1D卷积(需要学习额外的参数);
- 扩张卷积(需要学习额外的参数)。在他们的实验中,
EnWik8数据集上,卷积压缩效果最好; - 最常用的内存。
压缩式 transformer 有两个额外的训练损失:
-
自动编码损失 (无损压缩目标) 衡量我们能有多好地从压缩的内存重建原始内存
$$ \mathcal{L}_{ac} = \| \textbf{old_mem}^{(i)} - g(\textbf{new_cm}^{(i)}) \|_2 $$
其中 $g: \mathbb{R}^{[\frac{L}{c}] \times d} \to \mathbb{R}^{L \times d}$ 反转压缩函数 $f$。
-
注意重构损失 (有损目标) 重构基于内容的注意力与压缩的内存之间的注意力,并最小化差异:
$$ \mathcal{L}_{ar} = \|\text{attn}(\mathbf{h}^{(i)}, \textbf{old_mem}^{(i)}) − \text{attn}(\mathbf{h}^{(i)}, \textbf{new_cm}^{(i)})\|_2 $$
Transformer-XL 的内存大小为 $m$,具有最大时序范围 $m \times N$,其中 $N$ 是模型中的层数,和注意力成本 $\mathcal{O}(L^2 + Lm)$。相比之下,压缩的 transformer 有 $(m_m + c \cdot m_{cm}) \times N$ 的时序范围和 $\mathcal{O}(L^2 + L(m_m + m_{cm}))$ 的注意力成本。更大的压缩率 $c$ 在时序范围长度和注意力成本之间提供了更好的权衡。
从最旧到最新的注意力权重存储在三个位置:压缩内存 → 内存 → 因果遮蔽序列。在实验中,他们观察到从存储在常规内存中的最旧的激活到存储在压缩内存中的激活的注意力权重增加,这意味着网络正在学习保留重要信息。
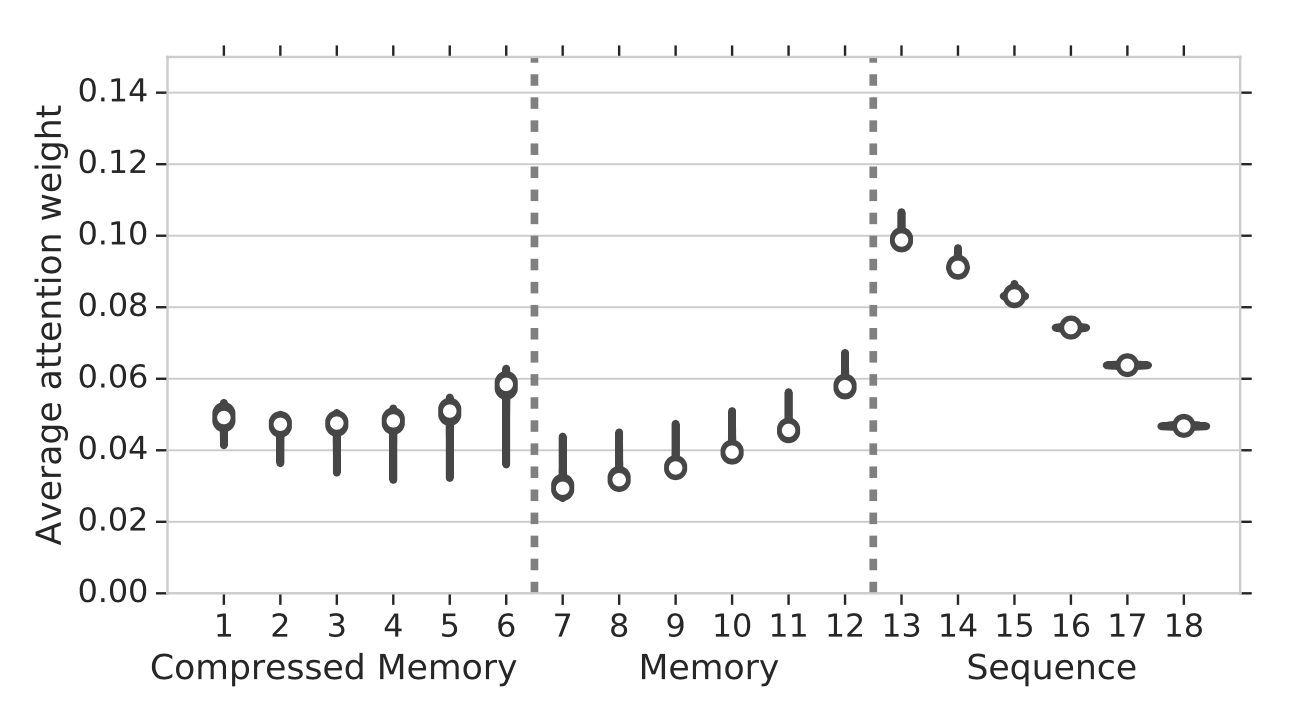
图 7. 注意力权重与一个标准偏差作为误差条,与内存位置从最旧(左)到最新(右)相对应。 (图片来源: Rae et al. 2019 )。
非可微分外部内存
$k$NN-LM (Khandelwal et al. 2020 ) 通过线性插值由两种模型预测的下一个标记的概率来增强预训练的LM,其中一个是单独的 $k$NN 模型。$k$NN 模型建立在一个外部键值存储上,该存储可以存储任何大的预训练数据集或OOD新数据集。这个数据存储是预处理的,以保存大量的对(语言模型嵌入表示的上下文, 下一个标记),最近邻检索发生在语言模型嵌入空间中。因为数据存储可以是巨大的,我们需要依赖于诸如 FAISS 或 ScaNN 这样的库进行快速的密集向量搜索。索引过程只发生一次,而且在推理时实现并行很容易。
在推理时,下一个标记的概率是两个预测的加权和:
$$ \begin{aligned} p(y \vert \mathbf{x}) &= \lambda \; p_\text{kNN}(y \vert \mathbf{x}) + (1- \lambda) \; p_\text{LM}(y \vert \mathbf{x}) \\ p_\text{kNN}(y \vert \mathbf{x}) &\propto \sum_{(k_i, w_i) \in \mathcal{N}} \mathbb{1}[y = w_i] \exp(-d(k_i, f(\mathbf{x}))) \end{aligned} $$
其中 $\mathcal{N}$ 包含一个由 $k$NN 检索的最近邻数据点的集合;$d(., .)$ 是例如L2距离的距离函数。
根据实验,较大的数据存储大小或较大的 $k$ 与更好的困惑度相关。权重标量 $\lambda$ 应该被调整,但通常它在与领域相关的数据和与领域无关的数据之间是期望更大的,而更大的数据存储可以承受更大的 $\lambda$。
SPALM(自适应半参数语言模型;Yogatama等人,2021 )融入了(1)Transformer-XL风格的外部上下文隐藏状态短时记忆和(2)$k$NN-LM风格的键值存储作为长时记忆。
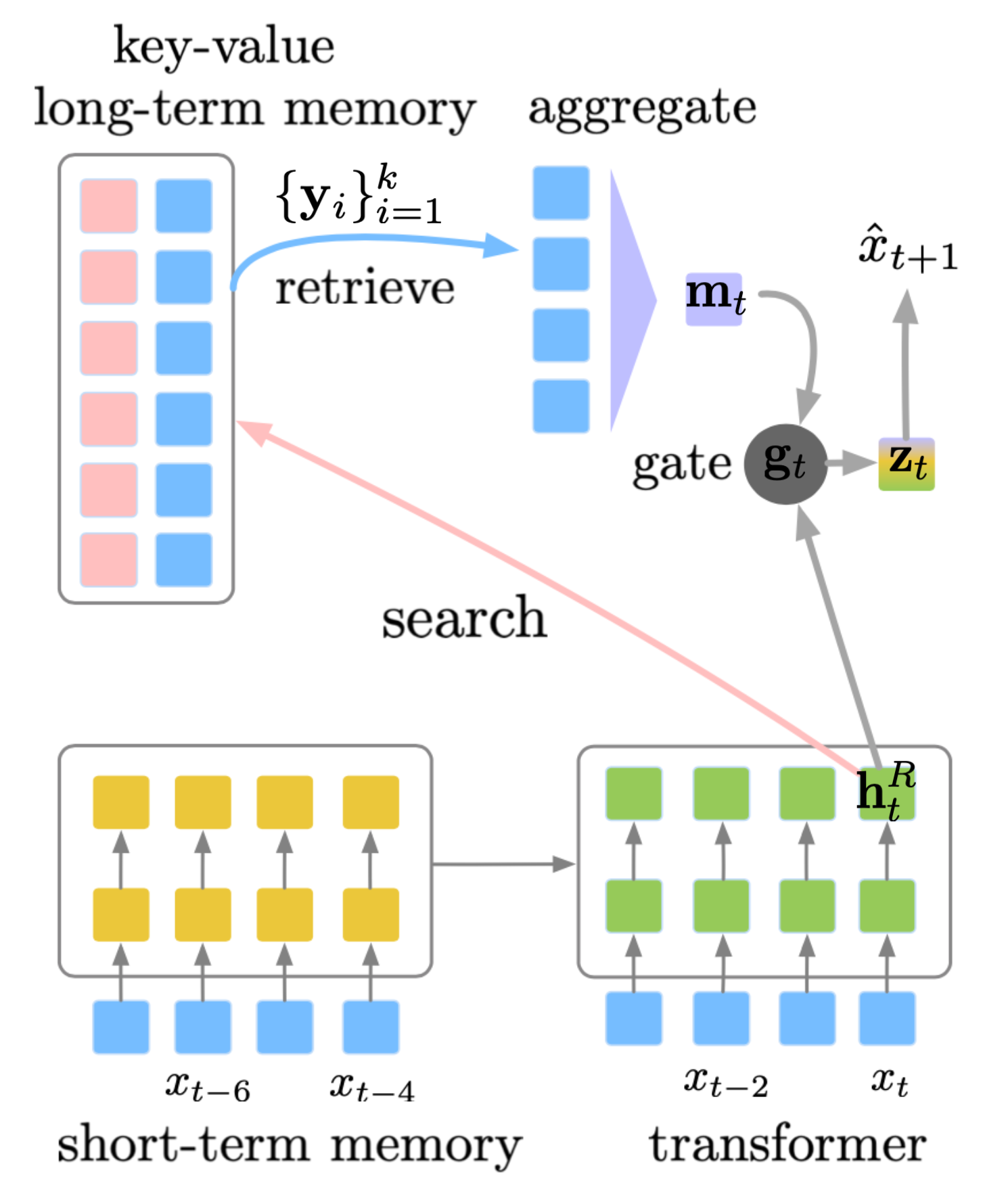
图 8. SPALM如何结合过去隐藏状态的上下文记忆(短期记忆)与外部键值数据存储(长期记忆)来支持更长的上下文的示意图。 (图片来源:Yogatama等人,2021 )。
SPALM运行$k$NN搜索来提取最相关上下文的$k$个令牌。对于每个令牌,我们可以获得由预训练的LM提供的相同的嵌入表示,记为$\{\mathbf{y}_i\}_{i=1}^k$。门控机制首先使用$\mathbf{h}^R_t$(令牌$x_t$在层$R$的隐藏状态)作为查询,通过一个简单的注意层聚合检索到的令牌嵌入,然后学习一个门控参数$\mathbf{g}_t$来在局部信息$\mathbf{h}^R_t$和长期信息$\mathbf{m}_t$之间进行平衡。
[公式省略]
其中$\mathbf{w}_g$是一个要学习的参数向量;$\sigma(.)$是sigmoid;$\mathbf{W}$是在输入和输出令牌之间共享的词嵌入矩阵。与$k$NN-LM不同,他们发现最近邻距离在检索令牌的聚合中并不有帮助。
在训练期间,长时记忆中的关键表示保持不变,由预训练的语言模型生成,但值编码器,即词嵌入矩阵,得到更新。
记忆型变换器 (Wu等人,2022 ) 在仅解码器的变换器的顶部堆栈附近添加了一个增强的$k$NN注意层。这个特殊的层维护了一个Transformer-XL风格的先进先出(FIFO)的过去键值对缓存。
同样的QKV值用于本地注意和$k$NN机制。$k$NN查找返回输入序列中每个查询的前$k$(键,值)对,然后它们通过自注意堆栈进行处理,计算检索值的加权平均值。两种类型的注意与可学习的每头门控参数结合在一起。为了防止值大小在分布中发生大的变化,缓存中的键和值都被规范化。
他们在记忆型变换器的实验中发现:
- 在某些实验中观察到,使用小内存训练模型,然后使用更大的内存进行微调,效果比从一开始就使用大内存进行训练更好。
- 仅在内存中有8k令牌的较小的记忆型变换器可以匹配具有5倍可训练参数的较大的原始变换器的困惑度。
- 增加外部记忆的大小可以一直提供增益,直到262K的大小。
- 非记忆变换器可以进行微调以使用记忆。
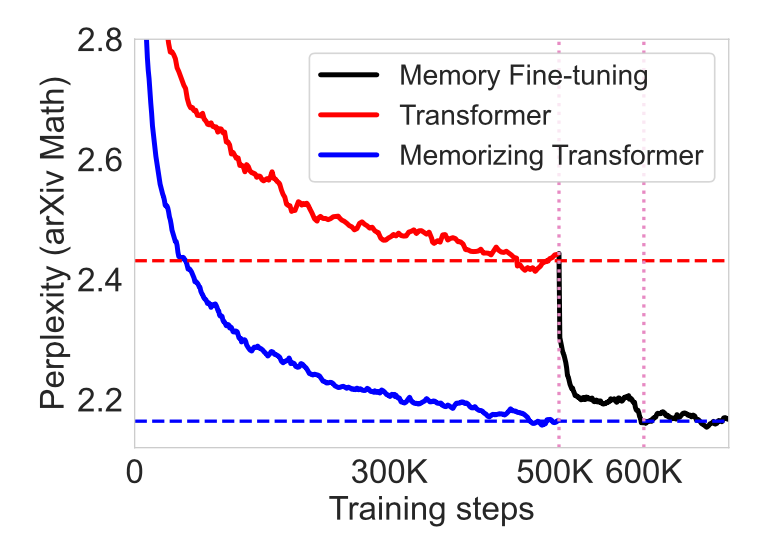
图 9. 使用键值记忆微调原始变换器可以达到与从头开始训练记忆型变换器相同的性能。 (图片来源:Wu等人,2022 )。
距离增强注意分数
距离感知变换器(DA-变换器; Wu等人,2021 ) 和 带线性偏见的注意 (ALiBi; Press等人,2022 ) 都是由类似的想法驱动的 - 为了鼓励模型推广到比模型训练上的更长的上下文,我们可以明确地将位置信息附加到基于键和查询令牌之间的距离的每对注意分数上。
请注意,默认的原始变换器中的位置编码只将位置信息添加到输入序列中,而后来改进的编码机制改变了每层的注意分数,例如旋转位置嵌入 ,它们采用了非常类似于距离增强注意分数的形式。
DA-Transformer (Wu 等人, 2021 ) 在每一层通过一个可学习的偏置乘以注意力得分,该偏置是键和查询之间的距离的函数。不同的注意力头使用不同的参数来区分对短期和长期上下文的不同偏好。给定两个位置,$i, j$,DA-Transformer 使用以下权重函数来修改自注意得分:
$$ \begin{aligned} \mathbf{R}^{(i)} &= \alpha_i \mathbf{R} \quad \text{where }R_{ij} = \vert i-j \vert\\ f(\mathbf{R}^{(i)}; \beta_i) &= \frac{1 + \exp(\beta_i)}{1 + \exp(\beta_i - \mathbf{R}^{(i)})} \\ \text{attn}(\mathbf{Q}^{(i)}, \mathbf{K}^{(i)}, \mathbf{V}^{(i)}) &= \text{row-softmax}\Big(\frac{\text{ReLU}(\mathbf{Q}^{(i)}\mathbf{K}^{(i)\top})f(\mathbf{R}^{(i)})}{\sqrt{d}}\Big) \mathbf{V}^{(i)} \end{aligned} $$
w其中 $\alpha_i$ 是一个可学习的参数,用于为头部加权相对距离,头部由上标 $^{(i)}$ 索引; $\beta_i$ 是一个可学习的参数,用于控制第 $i$ 个注意头相对于距离的上限和上升斜率。权重函数 $f(.)$ 的设计方式是:(1) $f(0)=1$;(2) 当 $\mathbf{R}^{(i)} \to -\infty$ 时,$f(\mathbf{R}^{(i)}) = 0$;(3) 当 $\mathbf{R}^{(i)} \to +\infty$ 时,$f(\mathbf{R}^{(i)})$ 是有界的;(4) 刻度是可调的;(5) 函数是单调的。由 $f(\mathbf{R}^{(i)})$ 带来的额外时间复杂度是 $\mathcal{O}(L^2)$,相对于自注意的时间复杂度 $\mathcal{O}(L^2 d)$ 很小。额外的内存消耗很小,约为 $\mathcal{O}(2h)$。
与其说乘数,不如说 ALiBi (Press 等人, 2022 ) 在查询键注意得分上加上了一个常数偏置项,这个偏置项与成对距离成正比。该偏置引入了一个强烈的最近偏好,并惩罚了距离太远的键。在不同的头部内,惩罚以不同的速率增加。 $$ \text{softmax}(\mathbf{q}_i \mathbf{K}^\top + \alpha_i \cdot [0, -1, -2, \dots, -(i-1)]) $$ where $\alpha_i$ is a head-specific weighting scalar. 与 DA-transformer 不同,$\alpha_i$ 不是学习的,而是固定为一个几何序列;例如,对于 8 个头部,$\alpha_i = \frac{1}{2}, \frac{1}{2^2}, \dots, \frac{1}{2^8}$。总体思路与相对位置编码旨在解决的问题非常相似。
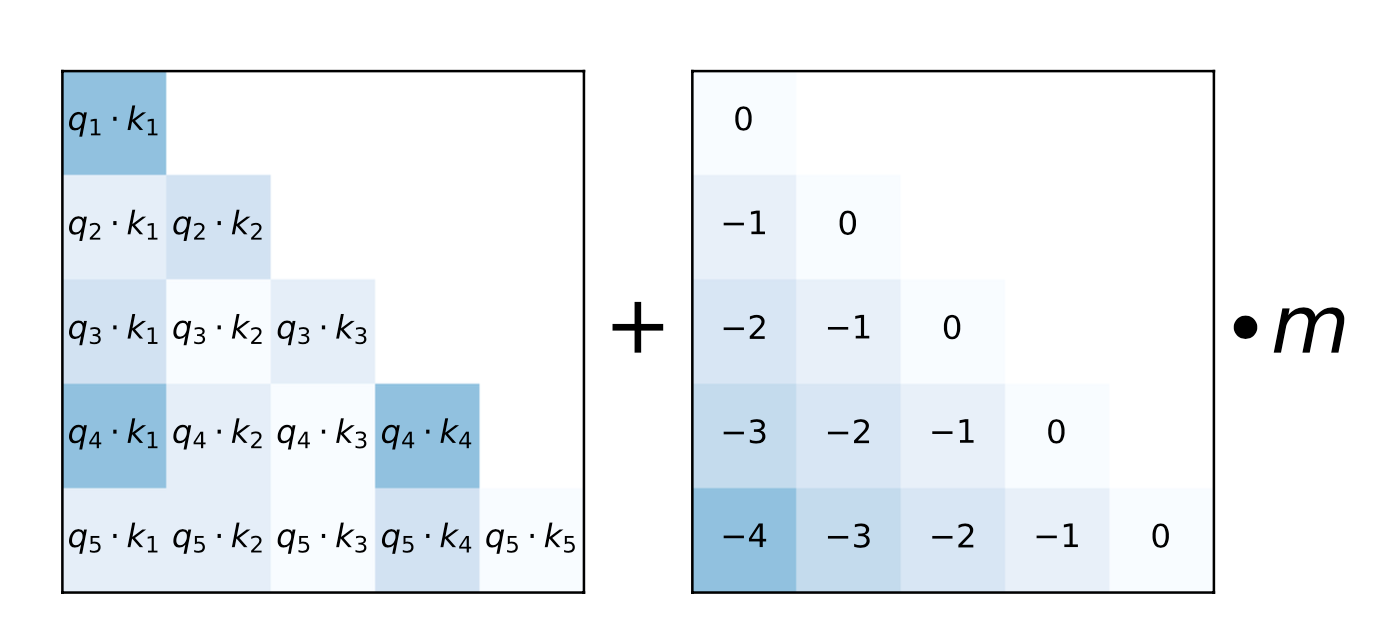
图 10. 如何使用位置偏置项增强 ALiBi 的注意得分的示意图。 (图片来源:Press 等人, 2021 )。
使用 ALiBi,Press 等人 (2022) 在训练期间针对上下文长度 1024 训练了一个 13 亿模型,并在推理时推算到 2046。
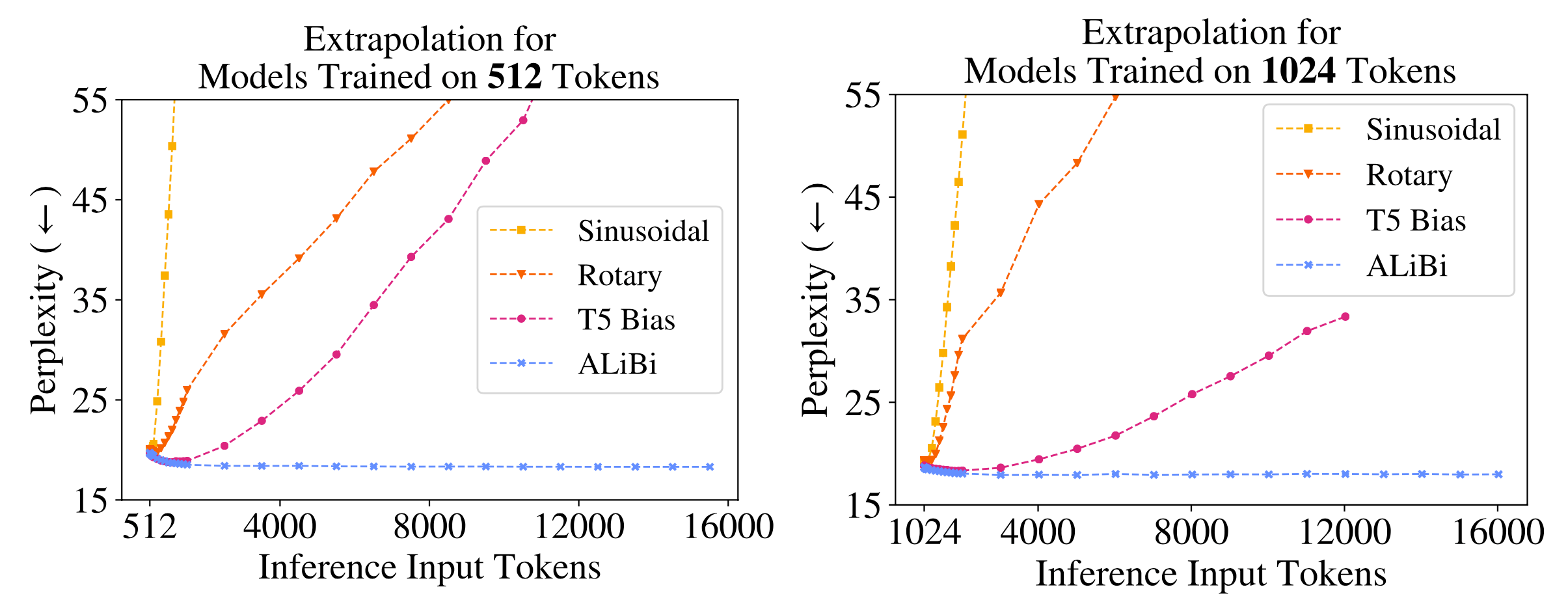
图 11. 对不同配置的变压器进行推断的外推实验,包括正弦位置编码、旋转位置编码、T5 中的简化相对位置编码和 ALiBi。所有模型都使用小的上下文长度进行训练,但推断运行了更长的上下文。 (图片来源:Press 等人, 2021 )。
使其具有循环性
通用变压器 (Dehghani 等人, 2019 ) 结合了变压器中的自注意和 RNN 中的循环机制,旨在从变压器的长期全局接受域和 RNN 的学习归纳偏见中受益。通用变压器不是通过固定数量的层,而是使用自适应计算时间 动态调整步数。如果我们固定步数,通用变压器等同于一个多层变压器,各层之间共享参数。
从高层次上看,通用变压器可以视为用于学习每个标记的隐藏状态表示的循环函数。循环函数在令牌位置之间并行演化,而位置之间的信息则通过自注意共享。
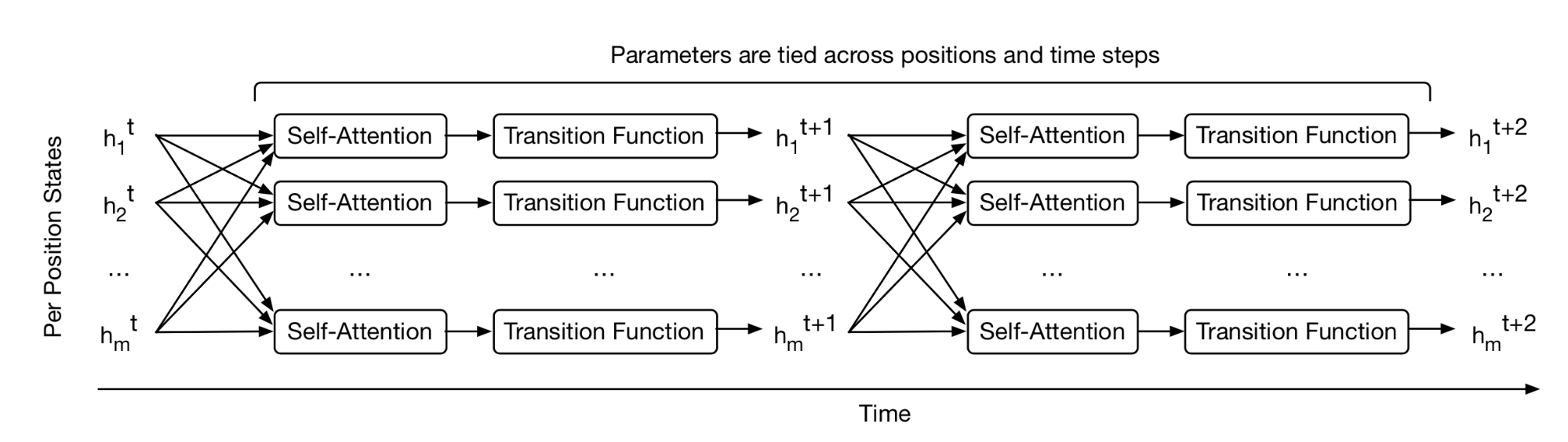
图 12. 通用变压器如何为每个位置反复细化一组隐藏状态表示的方式。 (图片来源:图 1 in Dehghani 等人, 2019 )。
对于长度为 $L$ 的输入序列,通用变压器在可调整的步数中迭代地更新表示 $\mathbf{h}^t \in \mathbb{R}^{L \times d}$。在第 0 步,$\mathbf{h}^0$ 被初始化为与输入嵌入矩阵相同。所有位置都在多头自注意机制中并行处理,然后通过一个循环过渡函数。
$$ \begin{aligned} \mathbf{A}^t &= \text{LayerNorm}(\mathbf{h}^{t-1} + \text{MultiHeadAttention}(\mathbf{h}^{t-1} + \mathbf{P}^t) \\ \mathbf{h}^t &= \text{LayerNorm}(\mathbf{A}^{t-1} + \text{Transition}(\mathbf{A}^t)) \end{aligned} $$
其中 $\text{Transition}(.)$ 是 separable convolution 或由两个按位置的(即应用于 $\mathbf{A}^t$ 的每一行)仿射变换 + 一个 ReLU 组成的完全连接的神经网络。
位置编码 $\mathbf{P}^t$ 使用 sinusoidal position signal ,但增加了一个时间维度:
$$ \text{PE}(i, t, \delta) = \begin{cases} \sin(\frac{i}{10000^{2\delta’/d}}) \oplus \sin(\frac{t}{10000^{2\delta’/d}}) & \text{if } \delta = 2\delta’\\ \cos(\frac{i}{10000^{2\delta’/d}}) \oplus \cos(\frac{t}{10000^{2\delta’/d}}) & \text{if } \delta = 2\delta’ + 1\\ \end{cases} $$
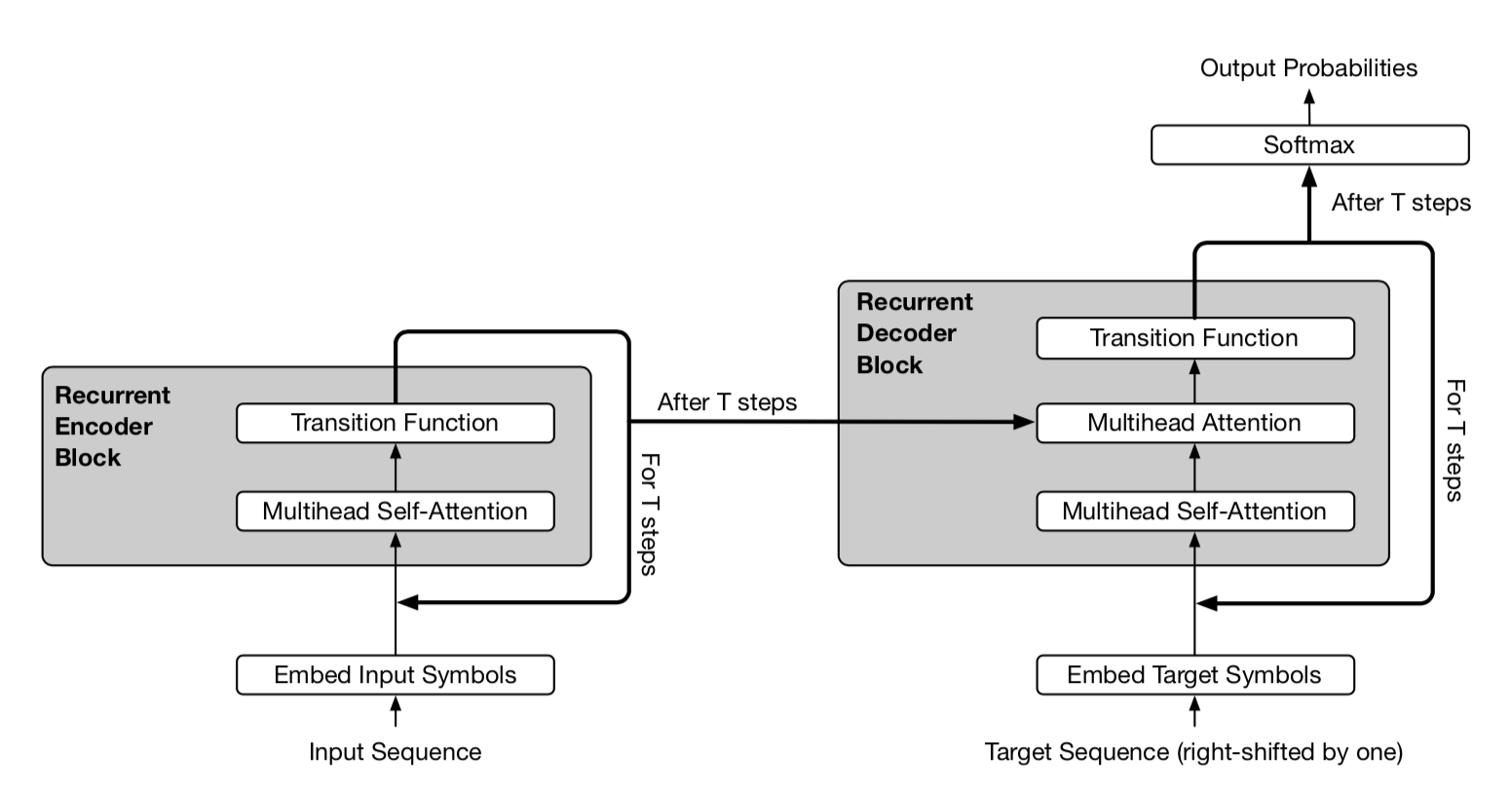
图 13. Universal Transformer 的简化描绘。编码器和解码器共享相同的基本循环结构。但解码器还注意到最终的编码器表示 $\mathbf{h}^T$。 (图片来源:Dehghani, et al. 2019 中的图 2)
在 Universal Transformer 的自适应版本中,递归步骤数 $T$ 由 ACT 动态确定。每个位置都配备了一个动态的 ACT 停止机制。一旦某个令牌的递归块停止,它就停止接受更多的递归更新,而只是将当前值复制到下一步,直到所有块都停止或模型达到最大步骤限制。
自适应建模
自适应建模是指能够根据不同输入调整计算量的机制。例如,某些令牌可能只需要局部信息,因此需要更短的注意力范围;或者某些令牌相对更容易预测,不需要通过整个注意力堆栈进行处理。
自适应注意力范围
Transformer 的一个关键优势是捕捉长期依赖关系的能力。取决于上下文,模型可能更倾向于有时关注更远的地方;或一个注意头可能与其他头有不同的注意模式。如果注意力范围可以灵活地调整其长度,并仅在需要时进一步关注,这将有助于减少计算和内存成本,以支持模型中更长的最大上下文大小。
这就是自适应注意力范围的动机。Sukhbaatar et al (2019) 提出了一种寻求最佳注意力范围的自我注意机制。他们假设同一上下文窗口中不同的注意头可能会不同地分配分数(见图 14),因此每个头的最佳范围将分别训练。
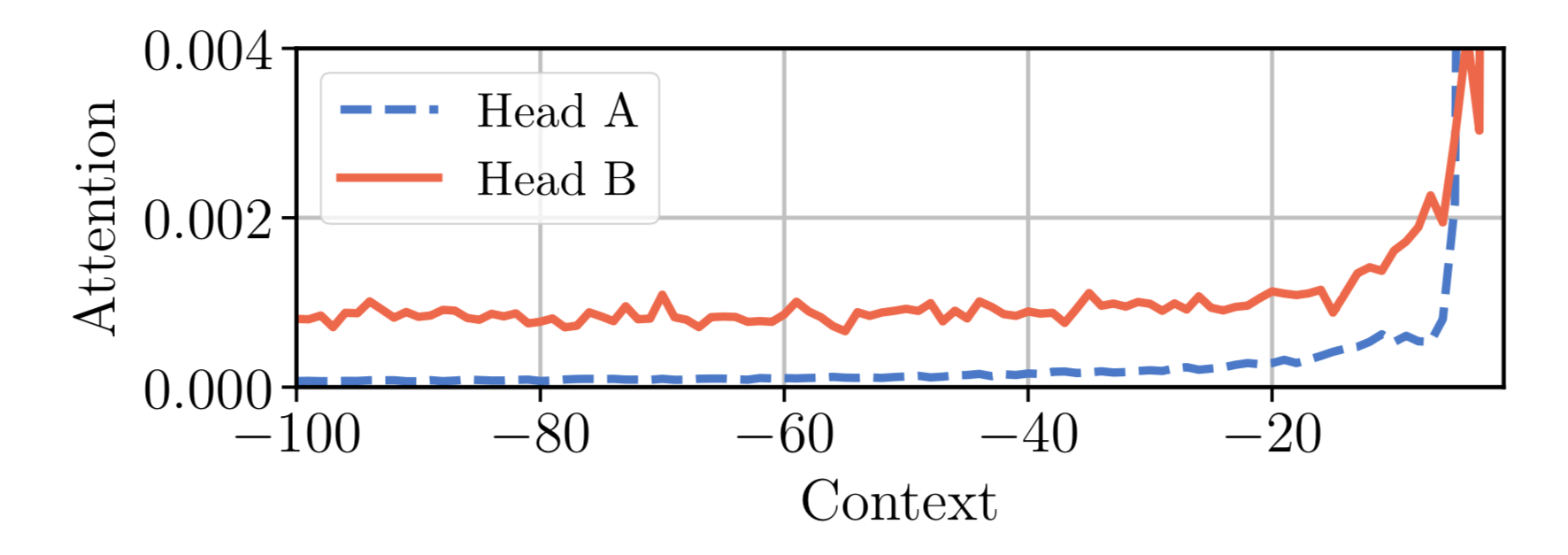
图 14. 同一模型中的两个注意力头 A & B 在同一上下文窗口内不同地分配注意力。头 A 更多地关注近期的令牌,而头 B 则均匀地回顾过去。 (图片来源:Sukhbaatar, et al. 2019 )
给定第 $i$ 个令牌,我们需要计算该令牌和其注意力范围大小为 $s$ 的其他键之间的注意权重:
$$ \begin{aligned} e_{ij} &= \mathbf{q}_i {\mathbf{k}_j}^\top \\ a_{ij} &= \text{softmax}(e_{ij}) = \frac{\exp(e_{ij})}{\sum_{r=i-s}^{i-1} \exp(e_{ir})} \\ \mathbf{y}_i &= \sum_{r=i-s}^{i-1}a_{ir}\mathbf{v}_r = \sum_{r=i-s}^{i-1}a_{ir}\mathbf{x}_r\mathbf{W}^v \end{aligned} $$
为了控制有效的可调注意力范围,添加了一个 soft mask function $m_z$,它将查询和键之间的距离映射到 [0, 1] 值。$m_z$ 由 $z \in [0, s]$ 参数化,并且 $z$ 是要学习的:
$$ m_z(x) = \text{clip}(\frac{1}{R}(R+z-x), 0, 1) $$
其中 $R$ 是一个超参数,用于定义 $m_z$ 的柔软度。
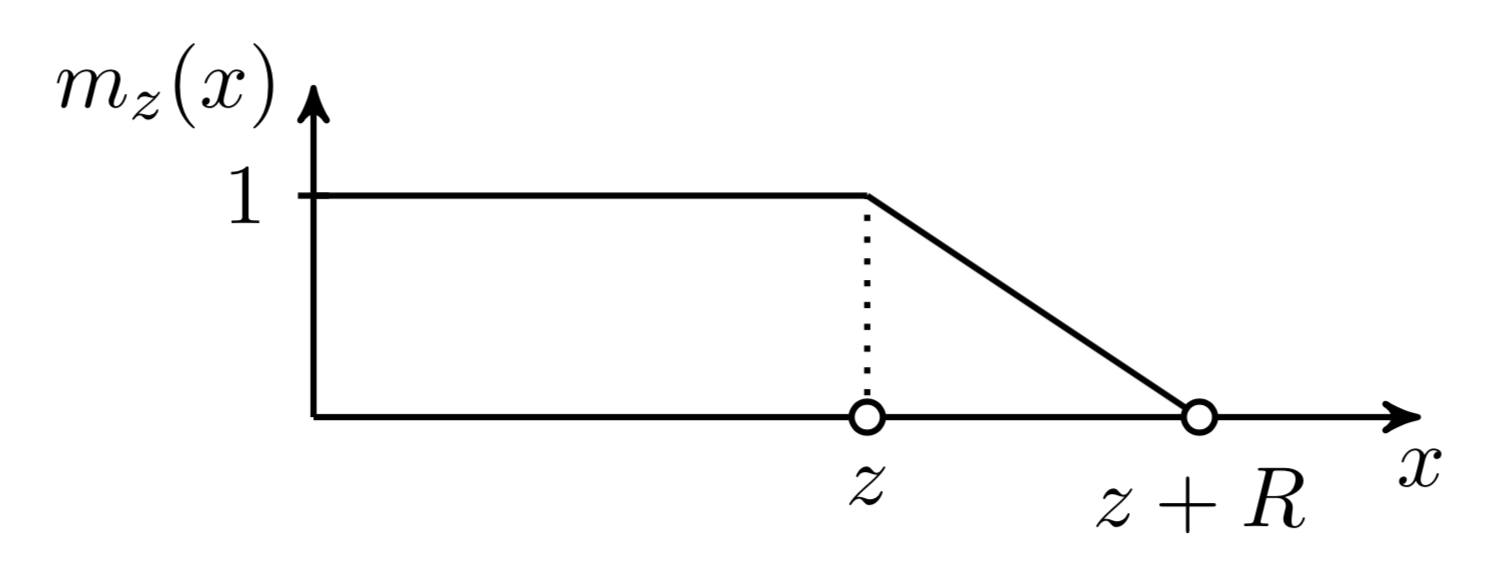
图 15. 自适应注意力跨度中使用的柔软遮罩函数。(图片来源:Sukhbaatar, 等. 2019 。)
柔软遮罩函数应用于注意力权重的softmax元素上:
$$ a_{ij} = \frac{m_z(i-j)\exp(s_{ij})}{\sum_{r=i-s}^{i-1}m_z(i-r) \exp(s_{ir})} $$
在上述公式中,$z$ 是可微分的,因此它与模型的其他部分一起训练。参数 $z^{(i)}, i=1, \dots, h$ 是_每个头部独立_地学习的。此外,损失函数对 $\sum_{i=1}^h z^{(i)}$ 有额外的L1惩罚。
使用自适应计算时间 ,这种方法可以进一步增强,以适应当前输入动态地具有灵活的注意力跨度长度。在时间 $t$ 的一个注意力头部的跨度参数 $z_t$ 是一个S形函数,$z_t = S \sigma(\mathbf{v} \cdot \mathbf{x}_t +b)$,其中向量 $\mathbf{v}$ 和偏置标量 $b$ 与其他参数一起学习。
在带有自适应注意力跨度的Transformer实验中,Sukhbaatar等人 (2019) 发现一个普遍的趋势,即较低的层不需要很长的注意力跨度,而较高的层中的几个注意力头部可能使用异常长的跨度。自适应注意力跨度还大大减少了FLOPS的数量,尤其是在一个有许多注意力层和大的上下文长度的大模型中。
深度自适应Transformer
在推理时,我们自然会认为某些令牌更容易预测,因此不需要像其他令牌那样进行大量计算。因此,我们可能只通过有限数量的层来处理其预测,以达到速度和性能之间的良好平衡。
深度自适应Transformer (Elabyad等人. 2020 ) 和 自信的自适应语言模型 (CALM; Schuster等人. 2022 ) 都受到这一思想的启发,并学习预测不同输入令牌所需的最佳层数。
深度自适应transformer (Elabyad等人. 2020 ) 将输出分类器附加到每一层,以根据该层的激活产生退出预测。分类器的权重矩阵可以在每一层都不同或在各层之间共享。在训练过程中,模型采样不同的退出序列,使得模型使用不同层的隐藏状态进行优化。学习目标结合了在不同层,$n=1, \dots, N$ 预测的可能性概率:
$$ \text{LL}^n_t = \log p(y_t \vert \mathbf{h}^n_{t-1}) \quad \text{LL}^n = \sum_{t=1}^{\vert\mathbf{y}\vert} LL^n_t $$
自适应深度分类器输出一个参数分布 $q_t$。它与oracle分布 $q^*_t$ 一起使用交叉熵损失进行训练。该论文探讨了如何学习这样一个分类器 $q_t$ 的三种配置。
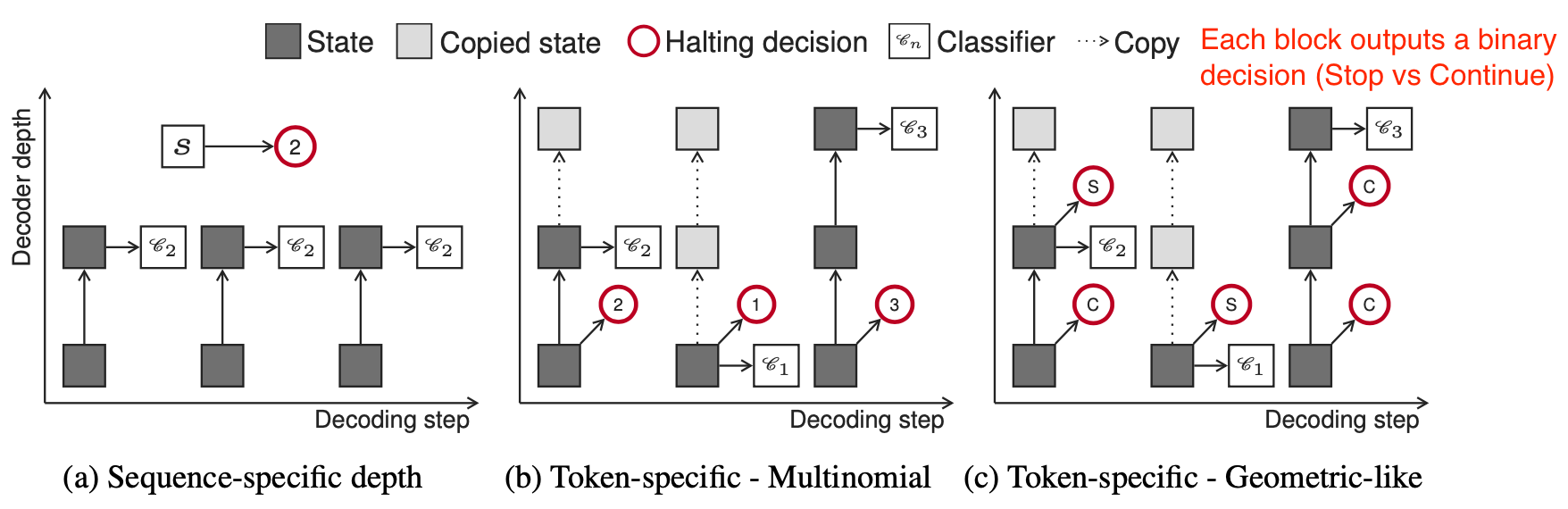
图 16. 三种类型的自适应深度分类器的示意图。 (图片来源:Elabyad等人. 2020 )。
-
序列特定深度分类器:同一序列的所有令牌共享相同的退出块。这取决于序列的编码器表示的平均值。给定长度为 $L$ 的输入序列 $\mathbf{x}$,分类器接收 $\bar{\mathbf{x}} = \frac{1}{L} \sum_{t=1}^L \mathbf{x}_t$ 作为输入,并输出一个 $N$ 维的多项式分布,对应于 $N$ 层。
$$ \begin{aligned} q(n | \mathbf{x}) &= \text{softmax}(\mathbf{W}_n \bar{\mathbf{x}} + b_n) \in \mathbb{R}^N \\ q_\text{lik}^*(\mathbf{x}, \mathbf{y}) &= \delta(\arg\max_n \text{LL}^n - \lambda n) \\ \text{或 } q_\text{corr}^*(\mathbf{x}, \mathbf{y}) &= \delta(\arg\max_n C^n - \lambda n) \text{ 其中 } C^n = |{t | y_t = \arg\max_y p(y | \mathbf{h}^n_{t-1})}| \end{aligned} $$
其中 $\delta$ 是 狄拉克 delta (单位脉冲) 函数,$-\lambda n$ 是一个正则项,用于鼓励较低层的退出。基础真值 $q^*$ 可以基于最大似然性 $q_\text{lik}^*$ 或正确性 $q_\text{corr}^*$ 以两种方式准备。
-
令牌特定深度分类器(多项式):每个令牌使用不同的退出块解码,预测基于第一个解码器隐藏状态 $\mathbf{h}^1_t$:
$$ q_t(n \vert \mathbf{x}, \mathbf{y}_{< t}) = \text{softmax}(\mathbf{W}_n \mathbf{h}^1_t + b_n) $$
-
令牌特定深度分类器(类几何):对于每一层的每一个令牌,都做一个二元的退出预测分布,$\mathcal{X}^n_t$。RBF核$\kappa(t, t’) = \exp(\frac{\vert t - t’ \vert^2}{\sigma})$被用来平滑预测,以纳入当前决策对未来时间步骤的影响。
$$ \begin{aligned} \mathcal{X}^n_t &= \text{sigmoid}(\mathbf{w}_n^\top \mathbf{h}^n_t + b_n)\quad \forall n \in [1, \dots, N-1] \\ q_t(n \vert \mathbf{x}, \mathbf{y}_{< t}) &= \begin{cases} \mathcal{X}^n_t \prod_{n’ < n} (1 - \mathcal{X}^{n’}_t) & \text{if } n < N \\ \prod_{n’ < N} (1 - \mathcal{X}^{n’}_t) & \text{otherwise} \end{cases} \\ q_\text{lik}^*(\mathbf{x}, \mathbf{y}) &= \delta(\arg\max_n \widetilde{\text{LL}}^n_t - \lambda n) \text{ where } \widetilde{\text{LL}}^n_t = \sum_{t’=1}^{\vert\mathbf{y}\vert}\kappa(t, t’) LL^n_{t’} \\ \text{or }q_\text{cor}^*(\mathbf{x}, \mathbf{y}) &= \delta(\arg\max_n \tilde{C}_t^n - \lambda n) \text{ where }C_t^n = \mathbb{1}[y_t = \arg\max_y p(y \vert \mathbf{h}^n_{t-1})],\; \tilde{C}^n_t = \sum_{t’=1}^{\vert\mathbf{y}\vert}\kappa(t, t’) C^n_{t’} \\ \end{aligned} $$
在推理时,需要校准做出退出决策的置信度阈值。深度自适应变换器在验证集上通过网格搜索找到这样的阈值。CALM (Schuster 等人, 2022 )应用了学习然后测试 (LTT) 框架(Angelopoulos 等人, 2021 )来确定一组有效的阈值,并选择最小值作为推理的阈值。除了训练每一层的退出分类器,CALM还探索了其他用于自适应深度预测的方法,包括softmax响应(即,前两个softmax输出之间的差异)和隐藏状态饱和度(即,$\cos(\mathbf{h}^n_t, \mathbf{h}^{n+1}_t)$)作为退出决策的置信度分数。他们发现softmax响应在推理加速方面效果最好。
高效注意力
传统变换器的计算和内存成本随着序列长度的增长而呈二次增长,因此很难应用于非常长的序列。对于变换器架构的许多效率提高都与自注意模块有关——使其更便宜、更小或运行更快。参见关于_高效变换器_的综述论文(Tay 等人, 2020 )。
稀疏注意模式
固定的本地上下文
为了使自注意力计算更为经济,一个简单的调整是限制每个令牌的注意力范围仅在本地上下文中,这样自注意力与序列长度线性增长。
这个想法首先由Image Transformer (Parmer, et al 2018 )引入,它将图像生成描述为使用编码器-解码器转换器架构的序列建模:
- 编码器生成源图像的上下文化的每像素通道表示;
- 然后解码器自动回归地生成输出图像,每个时间步骤一个像素通道。
我们把当前待生成像素的表示标记为查询$\mathbf{q}$。其他位置的表示用于计算$\mathbf{q}$的是关键向量$\mathbf{k}_1, \mathbf{k}_2, \dots$,它们共同形成一个记忆矩阵$\mathbf{M}$。$\mathbf{M}$的范围定义了像素查询$\mathbf{q}$的上下文窗口。
Image Transformer引入了两种类型的本地化$\mathbf{M}$,如下图所示。
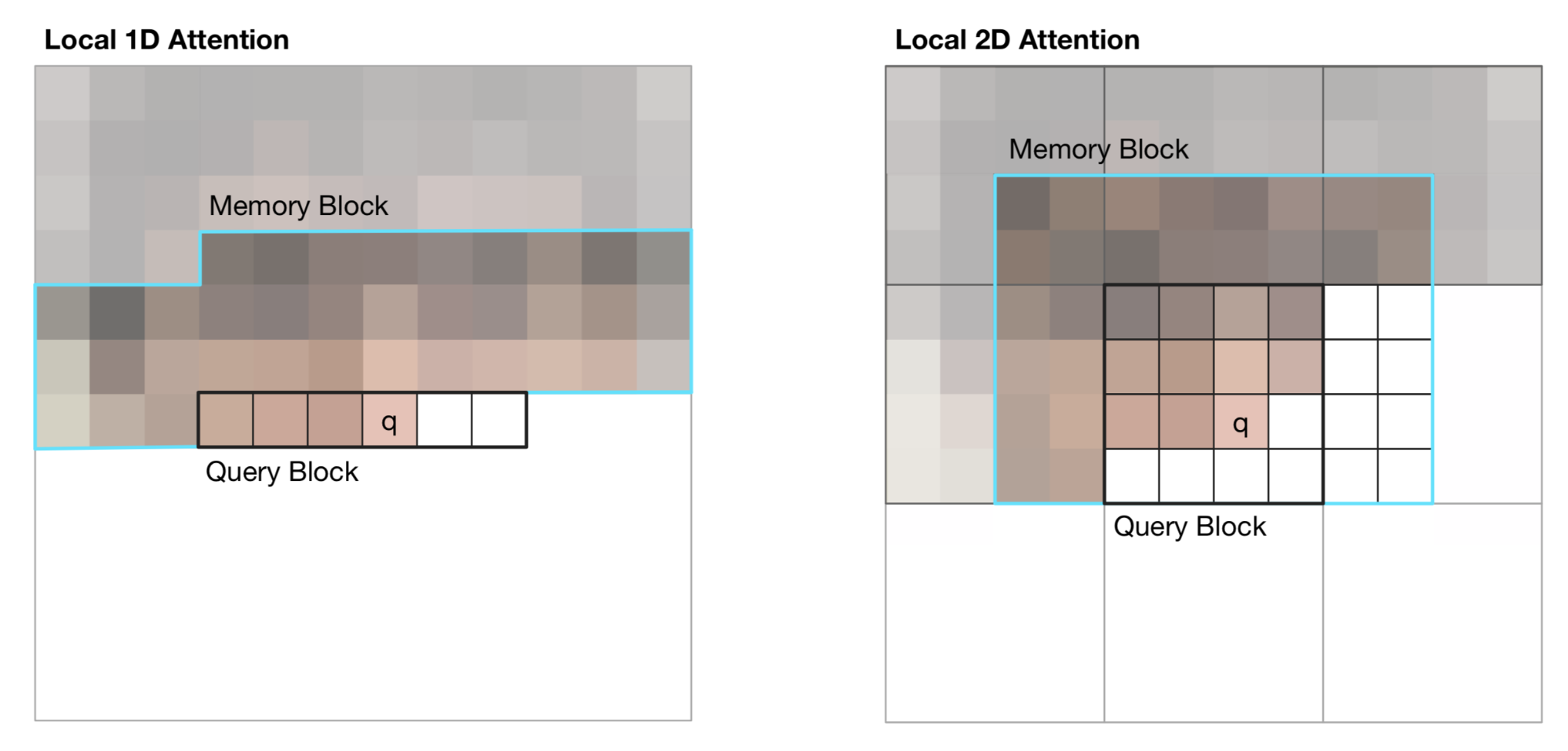
图17. Image Transformer 中视觉输入的1D和2D注意力范围的插图。黑线标记一个查询块,青色概述了像素q的实际注意力范围。(图片来源:Parmer et al, 2018 的图2)
-
1D 本地注意力:输入图像按raster scanning 的顺序展平,即从左到右,从上到下。线性化的图像被划分为不重叠的查询块。上下文窗口由与$\mathbf{q}$在同一个查询块中的像素和在此查询块之前生成的固定数量的额外像素组成。
-
2D 本地注意力:图像被划分为多个不重叠的矩形查询块。查询像素可以注意同一内存块中的所有其他像素。为了确保位于左上角的像素也有一个有效的上下文窗口,内存块分别向上、向左和向右扩展了固定的数量。
跨步上下文
Sparse Transformer (Child et al., 2019 )引入了_factorized self-attention_,通过稀疏矩阵分解,使得在现代硬件上训练具有数百层的稠密注意力网络成为可能,这些网络的序列长度可达16,384,否则这将是不可行的。
给定一个注意力连接模式集合$\mathcal{S} = \{S_1, \dots, S_n\}$,其中每个$S_i$记录了$i$-th查询向量关注的关键位置集。
$$ \begin{aligned} \text{Attend}(\mathbf{X}, \mathcal{S}) &= \Big( a(\mathbf{x}_i, S_i) \Big)_{i \in \{1, \dots, L\}} \\ \text{ where } a(\mathbf{x}_i, S_i) &= \text{softmax}\Big(\frac{(\mathbf{x}_i \mathbf{W}^q)(\mathbf{x}_j \mathbf{W}^k)_{j \in S_i}^\top}{\sqrt{d_k}}\Big) (\mathbf{x}_j \mathbf{W}^v)_{j \in S_i} \end{aligned} $$
注意,尽管 $S_i$ 的大小不固定,$a(\mathbf{x}_i, S_i)$的大小总是$d_v$,因此$\text{Attend}(\mathbf{X}, \mathcal{S}) \in \mathbb{R}^{L \times d_v}$。
在anto-regressive模型中,一个注意力范围被定义为$S_i = \{j: j \leq i\}$,因为它允许每个令牌注意过去的所有位置。
在分解自注意力中,集$S_i$被分解为一个依赖性的_tree_,这样对于每一对$(i, j)$,其中$j \leq i$,都有一条连接$i$返回$j$的路径,$i$可以直接或间接地注意到$j$。
确切地说,集合 $S_i$ 被划分为 $p$ 个 不重叠 的子集,其中第 $m$ 个子集表示为 $A^{(m)}_i \subset S_i, m = 1,\dots, p$。因此,从输出位置 $i$ 到任何 $j$ 的路径有最大长度 $p + 1$。例如,如果 $(j, a, b, c, \dots, i)$ 是 $i$ 和 $j$ 之间的索引路径,我们会有 $j \in A_a^{(1)}, a \in A_b^{(2)}, b \in A_c^{(3)}, \dots$,以此类推。
稀疏分解注意力
稀疏 Transformer 提出了两种分解注意力类型。当我们用2D图像输入作为例子看图10时,理解这些概念就会更加容易。
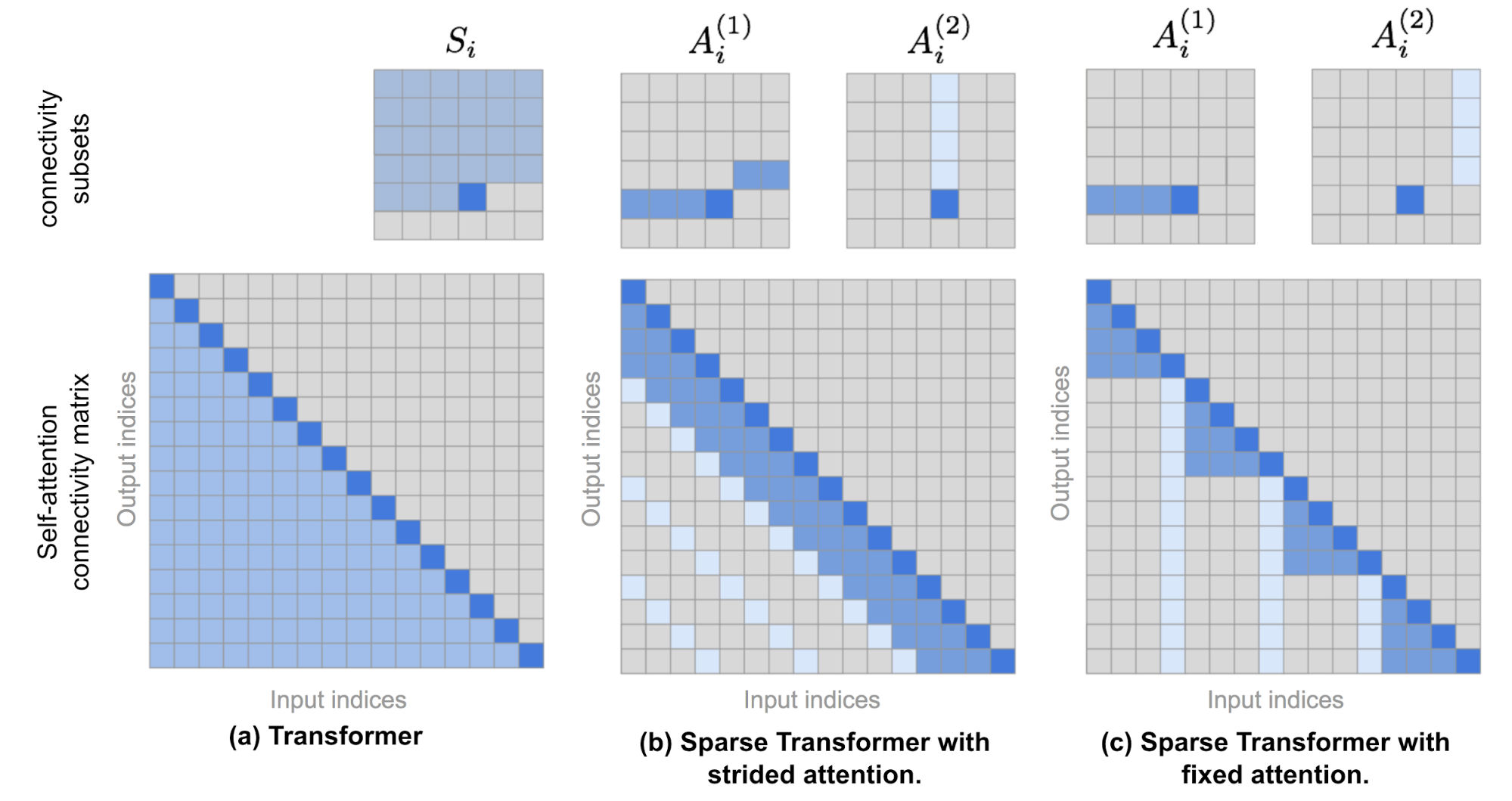
图 18. 上排展示了 (a) Transformer, (b) 稀疏 Transformer 带有跨步注意力, 和 (c) 稀疏 Transformer 带有固定注意力中的注意力连接模式。下排包含相应的自注意力连接矩阵。请注意,上排和下排的尺度不是一致的。(图片来源: Child et al., 2019 + 一些额外的注解。)
-
跨步 注意力,步长为 $\ell \sim \sqrt{n}$。这与图像数据结构对齐,因为图像数据结构与步长相对应。在图像的情况下,每个像素将关注按栅格扫描顺序的前 $\ell$ 个像素(自然地覆盖图像的整个宽度),然后这些像素会关注同一列中的其他像素(由另一个注意力连接子集定义)。
$$ \begin{aligned} A_i^{(1)} &= { t, t+1, \dots, i} \text{, where } t = \max(0, i - \ell) \ A_i^{(2)} &= {j: (i-j) \mod \ell = 0} \end{aligned} $$
-
固定 注意力。一小部分令牌总结了以前的位置并将该信息传播到所有未来的位置。
$$ \begin{aligned} A_i^{(1)} &= {j: \lfloor \frac{j}{\ell} \rfloor = \lfloor \frac{i}{\ell} \rfloor } \ A_i^{(2)} &= {j: j \mod \ell \in {\ell-c, \dots, \ell-1} } \end{aligned} $$
其中 $c$ 是一个超参数。如果 $c=1$,它限制了表示,而很多依赖于少数位置。论文选择了 $c\in \{ 8, 16, 32 \}$ 对于 $\ell \in \{ 128, 256 \}$。
在 Transformer 中使用分解自注意力
在 Transformer 架构中使用稀疏分解注意力模式有三种方式:
- 每个残差块一个注意力类型,然后交错它们,$ \text{attn}(\mathbf{X}) = \text{Attend}(\mathbf{X}, A^{(n \mod p)}) \mathbf{W}^o $,其中 $n$ 是当前残差块的索引。
- 设置一个单一的头,它关注所有分解的头关注的位置,$ \text{attn}(\mathbf{X}) = \text{Attend}(\mathbf{X}, \cup_{m=1}^p A^{(m)}) \mathbf{W}^o $。
- 使用多头注意力机制,但与普通的 Transformer 不同,每个头可能会采用上面提到的1或2的模式。 $ \rightarrow $ 这个选项通常表现最好。
稀疏 Transformer 还提出了一系列的变化,以便训练高达数百层的 Transformer,包括梯度检查点、在反向传播过程中重新计算注意力和 FF 层、混合精度训练、高效的块稀疏实现等。更多详情请查阅论文 或我之前关于放大模型训练技巧 的文章。
块状注意力 (Qiu et al. 2019 ) 引入了一个 稀疏块矩阵 ,只允许每个令牌关注其他令牌的一小部分。每个大小为 $L \times L$ 的注意力矩阵被划分为 $n \times n$ 的更小的块,大小为 $ \frac{L}{n}\times\frac{L}{n} $ ,并且稀疏块矩阵 $ \mathbf{M} \in \{0, 1\}^{L \times L} $ 由一个排列$ \pi $ 定义,记录块矩阵中每行的列索引。
$$ \begin{aligned} \text{attn}(\mathbf{Q}, \mathbf{K}, \mathbf{V}, \mathbf{M}) &= \text{softmax}\Big(\frac{\mathbf{Q}\mathbf{K}^\top}{\sqrt{d}} \odot \mathbf{M}\Big)\mathbf{V} \\ (\mathbf{A} \odot \mathbf{M})_{ij} &= \begin{cases} A_{ij} & \text{if } M_{ij} = 1 \\ -\infty & \text{if } M_{ij} = 0 \end{cases} \\ \text{where } M_{ij} &= \begin{cases} 1 & \text{if }\pi\big(\lfloor\frac{(i-1)n}{L} + 1\rfloor\big) = \lfloor\frac{(j-1)n}{L} + 1\rfloor \\ 0 & \text{otherwise} \end{cases} \end{aligned} $$
实际的块状注意力实现只将 QKV 存储为块矩阵,每个大小为 $n\times n$:
$$ \text{分块注意力}(\mathbf{Q}, \mathbf{K}, \mathbf{V}, \mathbf{M}) = \begin{bmatrix} \text{softmax}\big(\frac{\hat{\mathbf{q}}_1\hat{\mathbf{k}}_{\pi(1)}^\top}{\sqrt{d}} \Big)\hat{\mathbf{v}}_{\pi(1)} \\ \vdots \\ \text{softmax}\big(\frac{\hat{\mathbf{q}}_n\hat{\mathbf{k}}_{\pi(n)}^\top}{\sqrt{d}} \odot \Big)\hat{\mathbf{v}}_{\pi(n)} \\ \end{bmatrix} $$
其中,$\hat{\mathbf{q}}_i$、$\hat{\mathbf{k}}_i$ 和 $\hat{\mathbf{v}}_i$ 分别是 QKV 块矩阵中的第 $i$ 行。每个 $\mathbf{q}_i\mathbf{k}_{\pi(i)}^\top, \forall i = 1, \dots, n$ 的大小为 $\frac{N}{n}\times\frac{N}{n}$,因此分块注意力可以将注意力矩阵的内存复杂度从 $\mathcal{O}(L^2)$ 降低到 $\mathcal{O}(\frac{L}{n}\times\frac{L}{n} \times n) = \mathcal{O}(L^2/n)$。
本地和全局上下文的结合
ETC(扩展的Transformer构造; Ainslie等,2019 )、Longformer (Beltagy等,2020 ) 和 Big Bird (Zaheer等,2020 ) 模型在构建注意力矩阵时都结合了本地和全局上下文。所有这些模型都可以从现有的预训练模型中初始化。
ETC 的 全局-本地注意力 (Ainslie等,2019 ) 有两个输入,(1) 长度为 $n_l$ 的长输入 $\mathbf{x}^l$,它是常规输入序列;和 (2) 长度为 $n_g$ 的全局输入 $\mathbf{x}^g$,包含较少的辅助令牌,$n_g \ll n_l$。因此,基于这两个输入的方向性注意力,注意力被分为四个部分:g2g、g2l、l2g 和 l2l。由于 l2l 注意力部分可能非常大,所以它被限制为半径为 $w$ 的固定大小注意力跨度(即本地注意力跨度),并且 l2l 矩阵可以重塑为 $n_l \times (2w+1)$。
ETC 使用四个二进制矩阵来处理结构化输入,$\mathbf{M}^{g2g}$、$\mathbf{M}^{g2l}$、$\mathbf{M}^{l2g}$ 和 $\mathbf{M}^{l2l}$。例如,对于 g2g 注意力部分,注意力输出中的每个元素 $z^g_i \in \mathbb{R}^d$ 的格式为:
$$ \begin{aligned} a^{g2g}_{ij} = \frac{1}{\sqrt{d}} x^g_i \mathbf{W}^Q (x^g_j \mathbf{W}^K + P^K_{ij})^\top - (1- M^{g2g}_{ij})C \\ A^{g2g}_{ij} = \frac{\exp(a^{g2g}_{ij})}{\sum_{k=1}^{n_g} \exp(a^{g2g}_{ik})} \quad z^g_i = \sum^{n_g}_{j=1} A^{g2g}_{ij} x^g_j \mathbf{W}^V \end{aligned} $$
其中,$P^K_{ij}$ 是相对位置编码的可学习向量,而 $C$ 是一个非常大的常数(在论文中 $C=10000$),用于在遮罩关闭时偏移任何注意力权重。
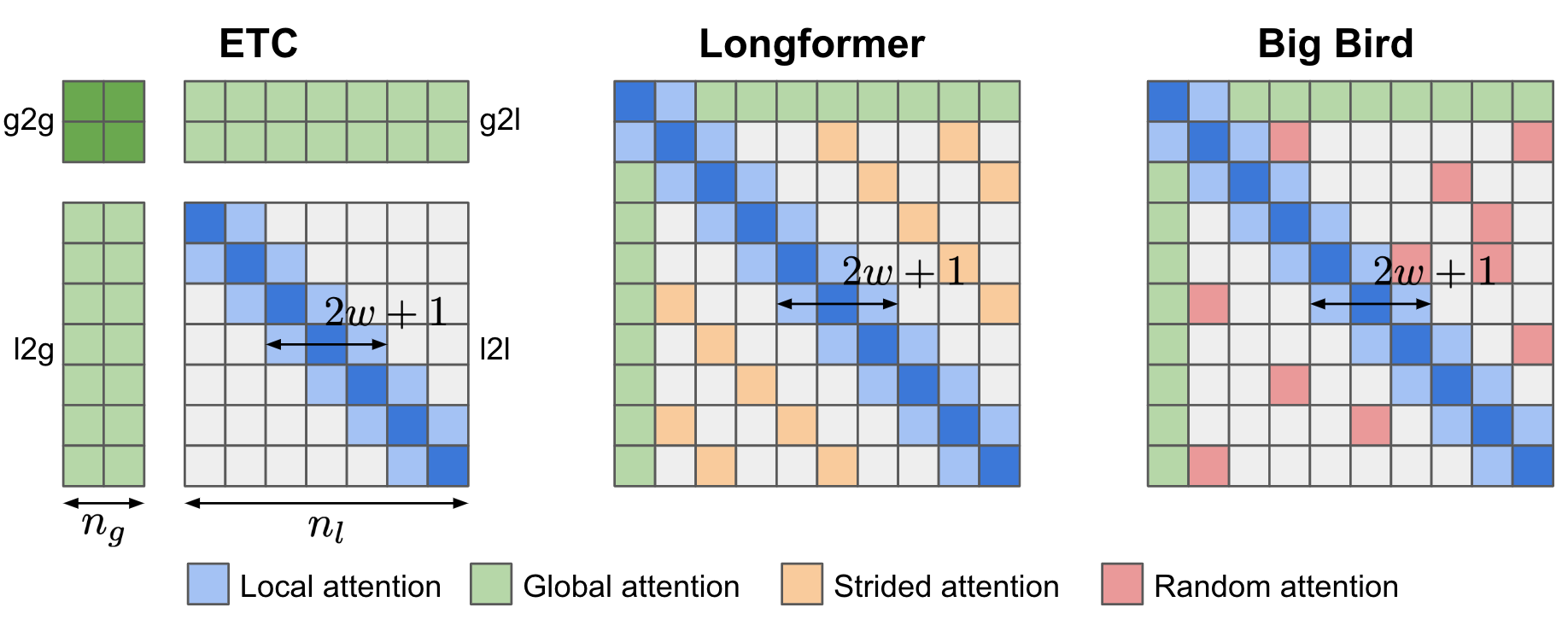
图 19. ETC、Longformer 和 Big Bird 的注意力模式。
ETC 中的另一个更新是在预训练阶段加入 CPC (对比预测编码) 任务,并使用 NCE loss ,除了 MLM 任务:当这个句子被掩盖时,一个句子的表示应该与它周围的上下文的表示相似。
ETC 的全局输入 $\mathbf{x}^g$ 是这样构造的:假设在长输入中有一些段(例如,按句子),每个段都带有一个辅助令牌来学习全局输入。使用相对位置编码 来标记带有令牌位置的全局段令牌。在一个方向上进行硬掩模(即,标记前后的令牌不同)在某些数据集中被发现可以带来性能增益。
Longformer的注意力模式包含三个部分:
- 局部注意力:与 ETC 相似,局部注意力由固定大小为 $w$ 的滑动窗口控制;
- 预选词汇的全局注意力:Longformer有一些预选词汇(如
[CLS]词汇)分配给全局注意力范围,即注意输入序列中的所有其他词汇。 - 扩张注意力:固定大小为 $r$ 且扩张大小为 $d$ 的扩张滑动窗口,类似于 Sparse Transformer。
Big Bird 与 Longformer 很相似,配备了局部注意力和少数预选词汇的全局注意力范围,但 Big Bird 用所有词汇关注一组随机词汇的新机制取代了扩张注意力。这种设计受到了注意力模式可以被视为有向图 和随机图 的观点的启发,随机图具有信息能够在任何两个节点之间快速流动的属性。
Longformer 在较低的层使用较小的窗口大小,在较高的层使用较大的窗口大小。消融研究显示,这种设置比反向或固定大小配置更有效。较低的层没有扩张滑动窗口,以更好地学习使用即时的局部上下文。Longformer 还有一个分阶段的训练程序,最初模型使用小窗口大小进行训练,从局部上下文中学习,然后后续的训练阶段窗口大小增加,学习速度降低。
基于内容的注意力
由 Reformer 提出的改进(Kitaev, et al. 2020 )旨在解决原始Transformer的以下痛点:
- 在自注意模块中,时间和内存复杂度都是二次方的。
- 具有 $N$ 层的模型的内存是单层模型的 $N$ 倍,因为我们需要存储激活用于反向传播。
- 中间的 FF 层通常相当大。
Reformer 提出了两个主要的变化:
- 用局部敏感哈希 (LSH) 注意力替换点积注意力,将复杂性从 $\mathcal{O}(L^2)$ 降低到 $\mathcal{O}(L\log L)$。
- 用可逆的残差层替换标准的残差块,这样在训练期间只需存储一次激活,而不是 $N$ 次(即与层数成正比)。
局部敏感哈希注意力
在注意力公式 的 $\mathbf{Q} \mathbf{K}^\top$ 部分,我们只对最大的元素感兴趣,因为只有大元素在 softmax 之后贡献很多。对于每个查询 $\mathbf{q}_i \in \mathbf{Q}$,我们正在寻找 $\mathbf{K}$ 中与 $\mathbf{q}_i$ 最接近的行向量。为了在高维空间中快速找到最近的邻居,Reformer 在其注意力机制中加入了局部敏感哈希 (LSH) 。
哈希方案 $x \mapsto h(x)$ 是局部敏感的,如果它保留了数据点之间的距离信息,这样接近的向量得到相似的哈希,而远离的向量得到非常不同的哈希。Reformer 采用了这样的哈希方案,给定一个固定的随机矩阵 $\mathbf{R} \in \mathbb{R}^{d \times b/2}$(其中 $b$ 是一个超参数),哈希函数是 $h(x) = \arg\max([xR; −xR])$。
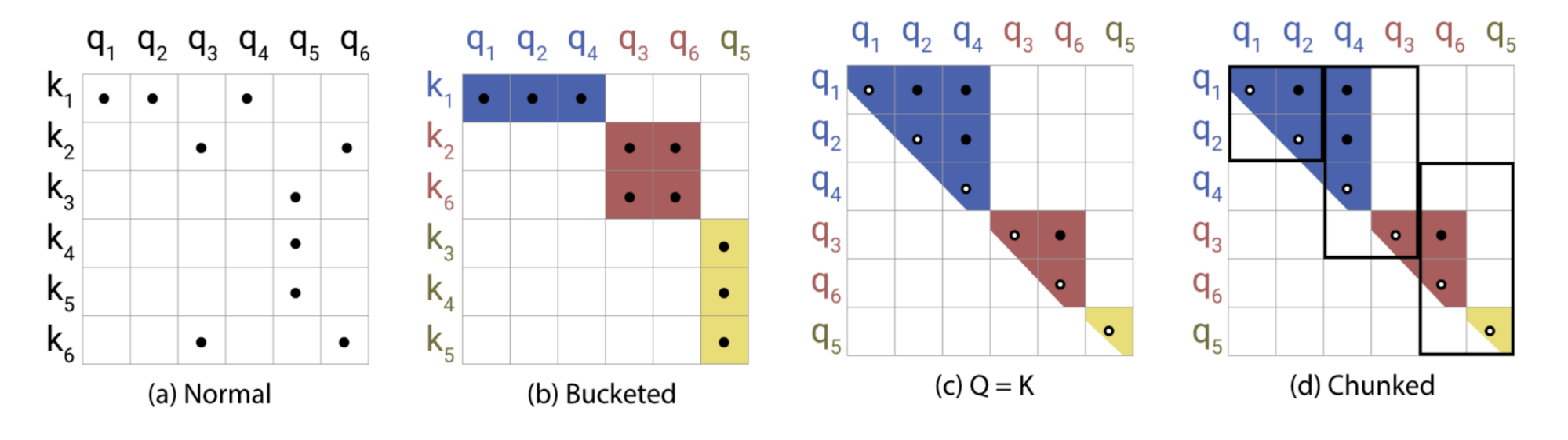
图 20. 局部敏感哈希 (LSH) 注意力机制示意图。(图片来源:Kitaev, 等. 2020 的图 1 的右半部分)
在 LSH 注意力中,一个查询只能关注与其位于同一个哈希桶的位置,$S_i = \{j: h(\mathbf{q}_i) = h(\mathbf{k}_j)\}$。如图 20 所示,它的执行过程为:
- (a) 对于完全注意力,注意力矩阵往往是稀疏的。
- (b) 使用 LSH,我们可以根据它们的哈希桶来对键和查询进行排序。
- (c) 设置 $\mathbf{Q} = \mathbf{K}$(确切地说 $\mathbf{k}_j = \mathbf{q}_j / |\mathbf{q}_j|$),这样在一个桶中的键和查询的数量就相等,这对于批处理更为简单。有趣的是,这种“共享-QK”配置不会影响 Transformer 的性能。
- (d) 对连续的 $m$ 个查询进行分组。
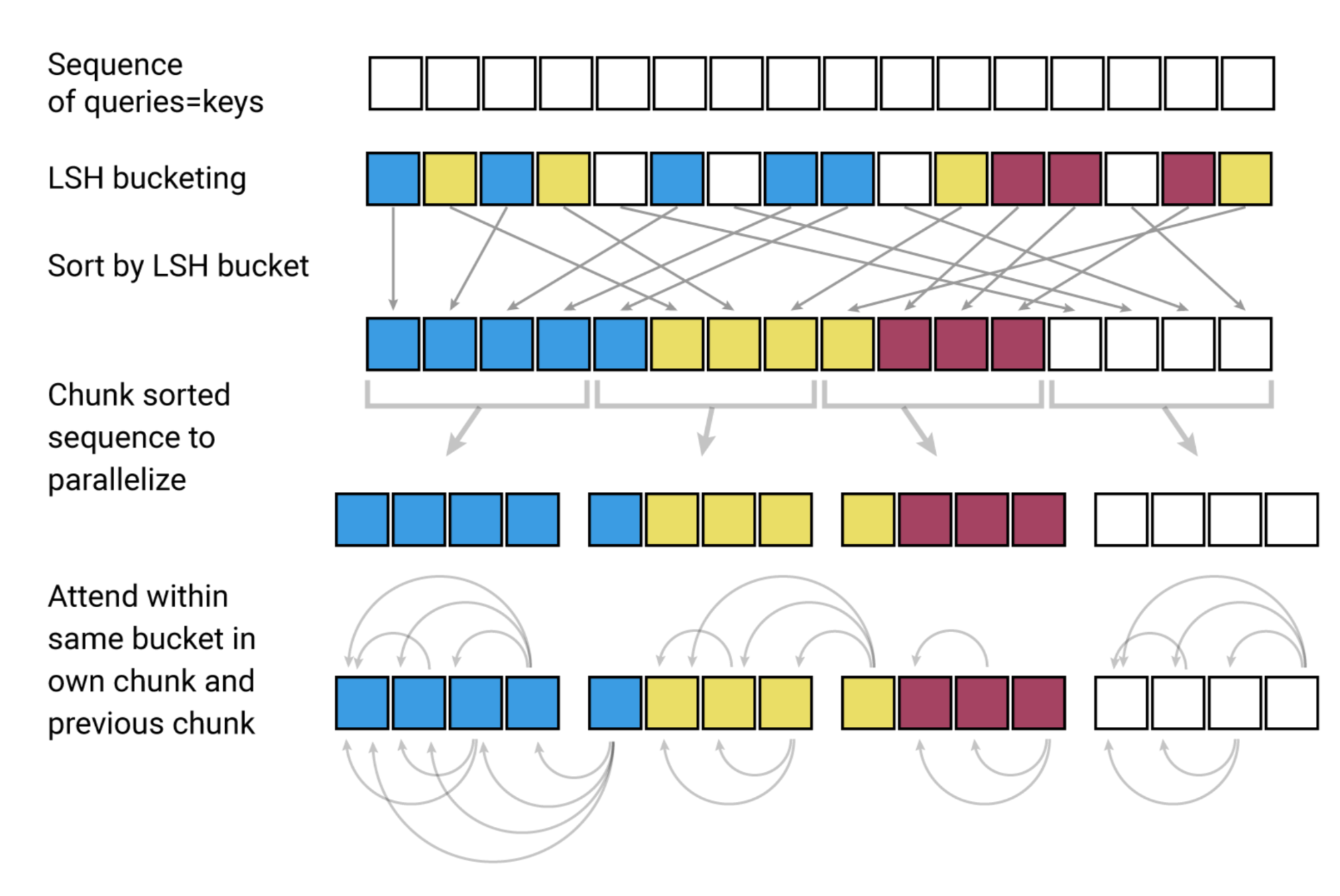
图 21. LSH 注意力由 4 个步骤组成:分桶、排序、块处理和注意力计算。(图片来源:Kitaev, 等. 2020 的图 1 的左半部分)
可逆残差网络
Reformer 的另一个改进是使用 可逆残差层(Gomez 等人. 2017 )。可逆残差网络的动机是设计网络结构,使得任意层的激活可以仅使用模型参数从下一层的激活中恢复。因此,我们可以通过在反向传播中重新计算激活而不是存储所有的激活来节省内存。
对于层 $x \mapsto y$,正常的残差层执行 $y = x + F(x)$,但可逆层将输入和输出都分成对 $(x_1, x_2) \mapsto (y_1, y_2)$,然后执行以下操作:
$$ y_1 = x_1 + F(x_2),\; y_2 = x_2 + G(y_1) $$
反转很简单:
$$ x_2 = y_2 - G(y_1), \; x_1 = y_1 − F(x_2) $$
Reformer 将这个想法应用于 Transformer,通过在可逆网络块中组合注意力 ($F$) 和前馈层 ($G$):
$$ Y_1 = X_1 + \text{Attention}(X_2), \; Y_2 = X_2 + \text{FeedForward}(Y_1) $$
通过将前馈计算分块,可以进一步减少内存:
$$ Y_2 = [Y_2^{(1)}; \dots; Y_2^{(c)}] = [X_2^{(1)} + \text{FeedForward}(Y_1^{(1)}); \dots; X_2^{(c)} + \text{FeedForward}(Y_1^{(c)})] $$
结果得到的可逆 Transformer 不需要在每一层都存储激活。
路由 Transformer (Roy 等人. 2021 ) 也基于对键和查询的内容进行聚类构建。它不像 LSH 使用静态哈希函数,而是使用在线 $k$-均值聚类,并将其与局部、时态稀疏注意力结合起来,将注意力复杂度从 $O(L^2)$ 降低到 $O(L^{1.5})$。
在路由注意力中,键和查询都使用 $k$-均值聚类方法进行聚类,有相同的质心集 $\boldsymbol{\mu} = (\mu_1, \dots, \mu_k) \in \mathbb{R}^{k \times d}$。查询被路由到分配给同一个质心的键。总复杂度为 $O(Lkd + L^2d/k)$,其中 $O(Lkd)$ 是用于运行聚类分配,而 $O(L^2d/k)$ 是用于注意力计算。聚类中心使用所有相关的键和查询的 EMA(指数移动平均)进行更新。
在路由 Transformer 的实验中,一些最佳配置只在模型的最后两层以及注意力头的一半中启用了路由注意力,而另一半使用了局部注意力。他们还观察到,局部注意力是一个非常强大的基线,更大的注意力窗口总是导致更好的结果。
低秩注意力
Linformer (Wang等,2020 ) 用一个_低秩_矩阵近似整个注意力矩阵,使时间和空间复杂度成为_线性_。Linformer不使用昂贵的SVD来识别低秩分解,而是为键和值矩阵分别添加两个线性投影$\mathbf{E}_i, \mathbf{F}_i \in \mathbb{R}^{L \times k}$,将它们的维度从$L \times d$减少到$k \times d$。只要$k \ll L$,注意力内存可以大大减少。
$$ \begin{aligned} \overline{\text{head}}_i &= \text{attn}(\mathbf{X}_q\mathbf{W}^q_i, \mathbf{E}_i\mathbf{X}_k\mathbf{W}^k_i, \mathbf{F}_i\mathbf{X}_v\mathbf{W}^v_i) \\ &= \underbrace{\text{softmax}\Big( \frac{\mathbf{X}_q\mathbf{W}^q_i (\mathbf{E}_i \mathbf{X}_k\mathbf{W}^k_i)^\top}{\sqrt{d}} \Big)}_{\text{低秩注意力矩阵 }\bar{A} \in \mathbb{R}^{k \times d}} \mathbf{F}_i \mathbf{X}_v\mathbf{W}^v_i \end{aligned} $$
可以应用其他技术进一步提高Linformer的效率:
- 投影层之间的参数共享,例如head-wise, key-value和layer-wise(跨所有层)共享。
- 在不同的层使用不同的$k$,因为在更高的层中的heads往往具有更倾斜的分布(低秩),因此我们可以在更高的层使用较小的$k$。
- 使用不同类型的投影;例如mean/max池化,卷积层与核和步幅$L/k$。
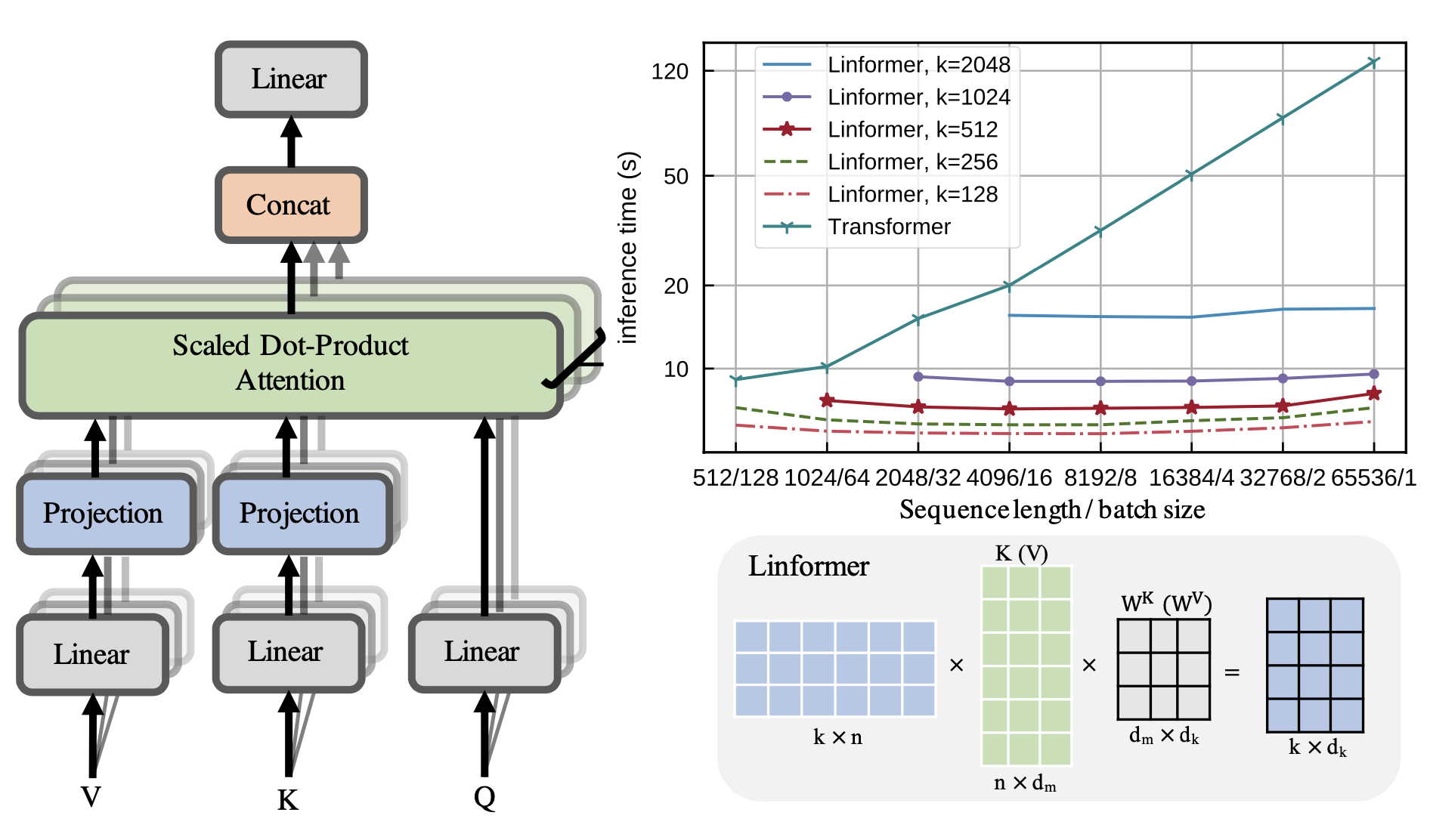
图 22. (左) Linformer为键和值添加了两个投影层。 (右) 随序列长度的推断时间的图。(图片来源:Wang等,2020 )。
随机特征注意力 (RFA; Peng等,2021 ) 依赖_随机特征方法_(Rahimi & Recht, 2007 )近似self-attention中的softmax操作,使用低秩特征图实现线性时间和空间复杂度。Performers (Choromanski等,2021 ) 也采用随机特征注意力,并在内核构造上进行了改进,以进一步减少内核近似误差。
RFA背后的主要定理来自Rahimi & Recht, 2007 :
设$\phi: \mathbb{R}^d \to \mathbb{R}^{2D}$为一个非线性变换:
$$ \phi(\mathbf{x}) = \frac{1}{\sqrt{D}}[\sin(\mathbf{w}_1^\top \mathbf{x}), \dots, \sin(\mathbf{w}_D^\top \mathbf{x}), \cos(\mathbf{w}_1^\top \mathbf{x}), \dots, \cos(\mathbf{w}_D^\top \mathbf{x})]^\top $$
当$d$-维随机向量$\mathbf{w}_i$是独立同分布的来自$\mathcal{N}(\mathbf{0}, \sigma^2\mathbf{I}_d)$时,$$ \mathbb{E}_{\mathbf{w}_i} [\phi(\mathbf{x}) \cdot \phi(\mathbf{y})] = \exp(-\frac{\| \mathbf{x} - \mathbf{y} \|^2}{2\sigma^2}) $$
$\exp(\mathbf{x} \cdot \mathbf{y})$的一个无偏估计是:
$$ \begin{aligned} \exp(\mathbf{x} \cdot \mathbf{y} / \sigma^2) &= \exp(\frac{1}{2\sigma^2}(\|\mathbf{x}\|^2 + \|\mathbf{y}\|^2 - \|\mathbf{x} - \mathbf{y}\|^2) \\ &= \exp(\frac{\|\mathbf{x}\|^2}{2\sigma^2}) \exp(\frac{\|\mathbf{y}\|^2}{2\sigma^2}) ( - \frac{\|\mathbf{x} - \mathbf{y}\|^2}{2\sigma^2}) \\ &\approx \exp(\frac{\|\mathbf{x}\|^2}{2\sigma^2}) \exp(\frac{\|\mathbf{y}\|^2}{2\sigma^2})\;\phi(\mathbf{x})\cdot\phi(\mathbf{y}) \\ &= \exp(\frac{1}{\sigma^2})\;\phi(\mathbf{x})\cdot\phi(\mathbf{y}) & \text{; 单位向量} \end{aligned} $$
然后我们可以如下写出注意力函数,其中$\otimes$是外积操作,$\sigma^2$是温度:
$$ \begin{aligned} \text{attn}(\mathbf{q}_t, \{\mathbf{k}_i\}, \{\mathbf{v}_i\}) &= \sum_i \frac{\exp(\mathbf{q}_t\cdot\mathbf{k}_i/\sigma^2)}{\sum_j \exp(\mathbf{q}_t\cdot\mathbf{k}_j/\sigma^2)}\mathbf{v}_i^\top \approx \sum_i \frac{\phi(\mathbf{q}_t)\phi(\mathbf{k}_i)\mathbf{v}_i^\top}{\sum_j \phi(\mathbf{q}_t)\phi(\mathbf{k}_j)} \\ &= \color{green}{\frac{\phi(\mathbf{q}_t)^\top \sum_i \phi(\mathbf{k}_i)\otimes\mathbf{v}_i}{\phi(\mathbf{q}_t)^\top \sum_j \phi(\mathbf{k}_j)} = \text{RFA}(\mathbf{q}_t, \{\mathbf{k}_i\}, \{\mathbf{v}_i\})} \end{aligned} $$
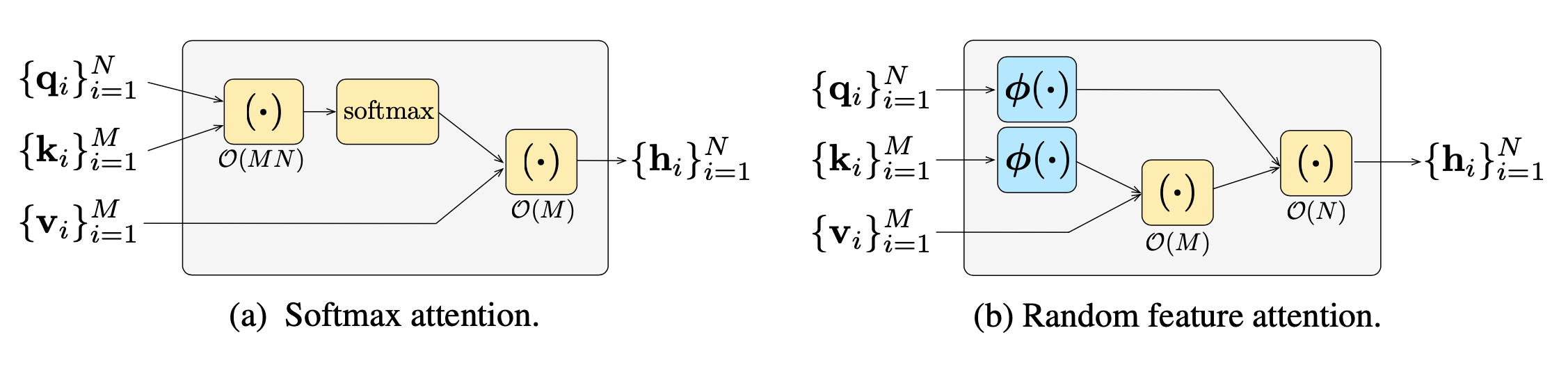
图23. (左) 默认的softmax操作的计算顺序。(右) 使用随机特性关注时的计算顺序,比默认的softmax更便宜。(图片来源: Peng et al. 2021 )。
Causal Attention RFA 在时间步骤 $ t $ 的令牌仅关注早期的键和值 ${\mathbf{k}_i}_{i \leq t}, {\mathbf{v}_i}_{i \leq t}$。我们使用变量元组,$(\mathbf{S}_t \in \mathbb{R}^{2D \times d}, \mathbf{z} \in \mathbb{R}^{2D})$,跟踪时间步骤 $ t $ 的隐藏状态历史,类似于RNNs:
$$ \begin{aligned} &\text{causal-RFA}(\mathbf{q}_t, \{\mathbf{k}_i\}_{i \leq t}, \{\mathbf{v}_i\}_{i \leq t}) = \frac{\phi(\mathbf{q}_t)^\top \mathbf{S}_t}{\phi(\mathbf{q}_t) \cdot \mathbf{z}_t} \\ &\text{where } \mathbf{S}_t = \mathbf{S}_{t-1} + \phi(\mathbf{k}_t)\otimes\mathbf{v}_t, \quad \mathbf{z}_t = \mathbf{z}_{t-1} + \phi(\mathbf{k}_t) \end{aligned} $$
其中 $ 2D $ 是 $ \phi(.) $ 的大小,而 $ D $ 应该不小于模型大小 $ d $ 以获得合理的近似。
RFA 在自回归解码中导致了显著的加速,而记忆复杂性主要取决于构建核心 $ \phi(.) $ 时 $ D $ 的选择。
Performer 使用正随机特征映射修改随机特征关注,以减少估计误差。它还保持随机采样的 $ \mathbf{w}_1, \dots, \mathbf{w}_D $ 与进一步减少估计器的方差正交。
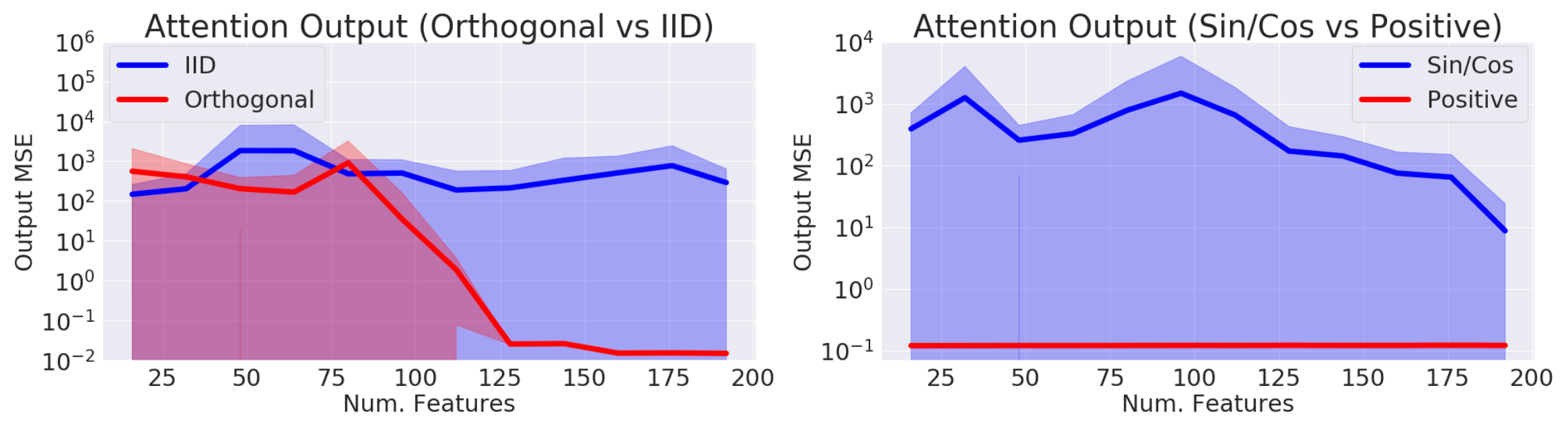
图24. 使用 (左) i.i.d 与正交特征和 (右) sin/cos 与正随机特征时的近似误差比较。(图片来源: Choromanski et al. 2021 )。
为强化学习设计的Transformers
自注意机制避免将整个过去压缩到固定大小的隐藏状态,并且与RNN相比,不太容易产生消失或爆炸的梯度。强化学习任务肯定可以从这些特性中受益。然而,即使在有监督的学习中训练Transformer也很困难,更不用说在RL上下文中了。毕竟,单独稳定和训练一个LSTM代理可能相当具有挑战性。
Gated Transformer-XL (GTrXL; Parisotto, et al. 2019 ) 是一种尝试使用Transformer进行RL的方法。在Transformer-XL 的基础上,GTrXL 通过两个改变成功地稳定了训练:
- 层标准化仅应用于残余模块的输入流,但不应用于快捷流。这种重新排序的主要好处是允许原始输入从第一层流向最后一层。
- 用GRU式(门控循环单元; Chung et al., 2014 )门控 机制替换了残留连接。
$$ \begin{aligned} r &= \sigma(W_r^{(l)} y + U_r^{(l)} x) \\ z &= \sigma(W_z^{(l)} y + U_z^{(l)} x - b_g^{(l)}) \\ \hat{h} &= \tanh(W_g^{(l)} y + U_g^{(l)} (r \odot x)) \\ g^{(l)}(x, y) &= (1-z)\odot x + z\odot \hat{h} \end{aligned} $$
门控功能的参数被明确地初始化为接近于恒等映射 - 这就是为什么有一个$b_g$项的原因。当$b_g > 0$时,这大大加速了学习速度。
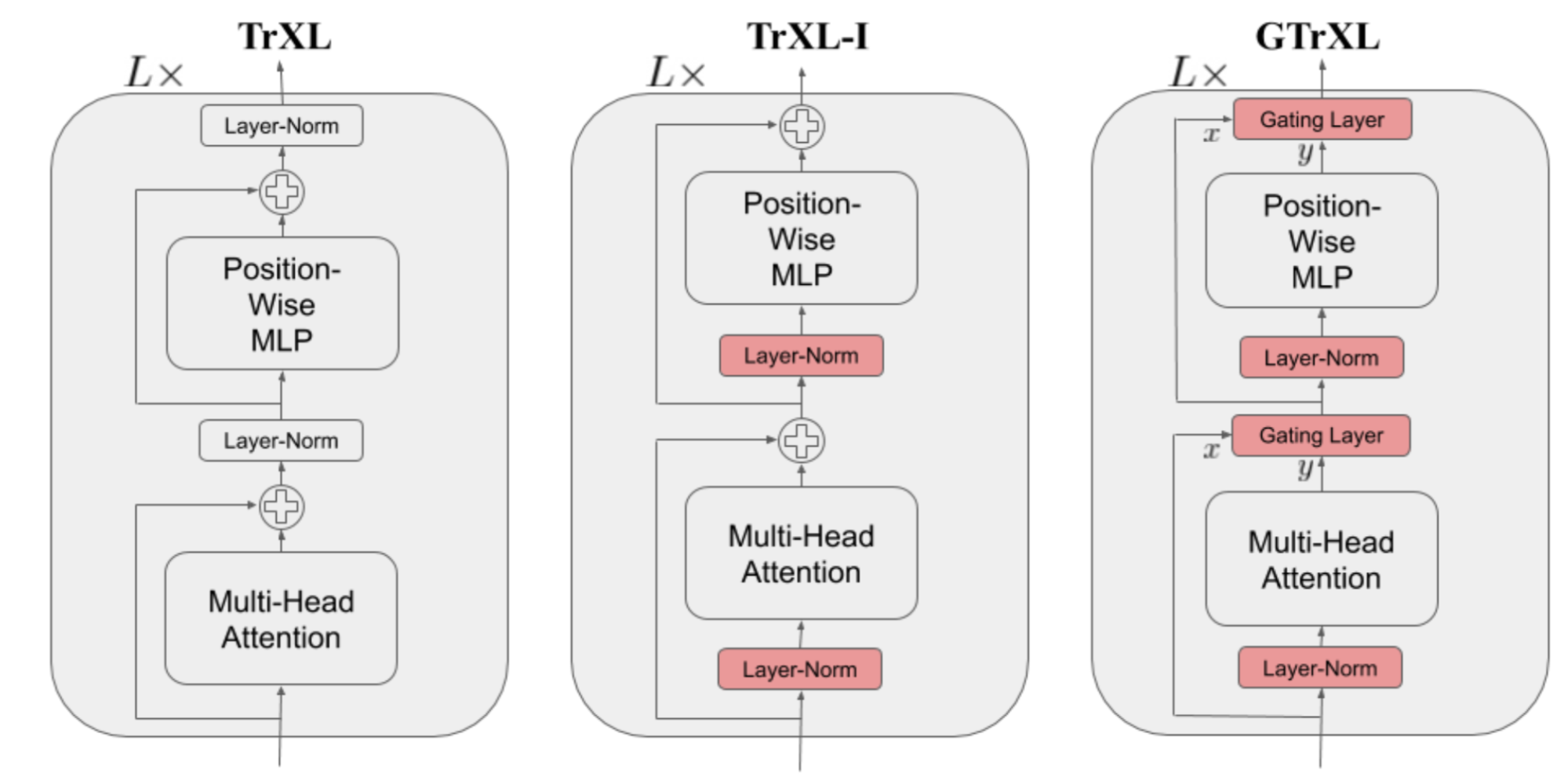
图 25. Transformer-XL、重新排序的Transformer-XL层规范和带门控的Transformer-XL的模型架构比较。(图片来源:Parisotto等,2019 中的图1)
决策Transformer (DT; Chen等,2021 )将强化学习问题描述为_条件序列建模_的过程,根据所需的回报、过去的状态和动作输出最佳动作。因此,使用Transformer架构变得非常直接。决策Transformer用于离策略RL ,其中模型只能访问由其他策略收集的固定轨迹集合。
为了鼓励模型学习如何行动以达到所需的回报,它用所期望的未来回报$\hat{R} = \sum_{t’=t}^T r_{t’}$来供给模型,而不是当前的奖励。轨迹由一系列的三元组组成,(要达到的回报$\hat{R}_t$,状态$s_t$,动作$a_t$),它被用作Transformer的输入序列:
$$ \tau = (\hat{R}_1, s_1, a_1, \hat{R}_2, s_2, a_2, \dots, \hat{R}_T, s_T, a_T) $$
为return-to-go、状态和动作分别添加并训练了三个线性层,以提取token嵌入。预测头学习预测与输入token $s_t$相对应的$a_t$。对于离散动作,使用交叉熵损失进行训练,对于连续动作,使用MSE。预测状态或return-to-go在他们的实验中没有被发现可以帮助提高性能。
实验将DT与几个无模型的RL算法基线进行了比较,并显示出:
- 在低数据环境下,DT比行为克隆更有效;
- DT可以很好地建模回报分布;
- 拥有一个长期上下文对于获得好的结果至关重要;
- DT可以处理稀疏奖励。
Citation
Cited as:
Weng, Lilian. (Jan 2023). The transformer family version 2.0. Lil’Log. https://lilianweng.github.io/posts/2023-01-27-the-transformer-family-v2/ .
Or
@article{weng2023transformer,
title = "The Transformer Family Version 2.0",
author = "Weng, Lilian",
journal = "lilianweng.github.io",
year = "2023",
month = "Jan",
url = "https://lilianweng.github.io/posts/2023-01-27-the-transformer-family-v2/"
}
References
[1] Ashish Vaswani, et al. “Attention is all you need." NIPS 2017.
[2] Rami Al-Rfou, et al. “Character-level language modeling with deeper self-attention." AAAI 2019.
[3] Olah & Carter, “Attention and Augmented Recurrent Neural Networks” , Distill, 2016.
[4] Sainbayar Sukhbaatar, et al. “Adaptive Attention Span in Transformers” . ACL 2019.
[5] Rewon Child, et al. “Generating Long Sequences with Sparse Transformers” arXiv:1904.10509 (2019).
[6] Nikita Kitaev, et al. “Reformer: The Efficient Transformer” ICLR 2020.
[7] Alex Graves. (“Adaptive Computation Time for Recurrent Neural Networks”)[https://arxiv.org/abs/1603.08983]
[8] Niki Parmar, et al. “Image Transformer” ICML 2018.
[9] Zihang Dai, et al. “Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context." ACL 2019.
[10] Aidan N. Gomez, et al. “The Reversible Residual Network: Backpropagation Without Storing Activations” NIPS 2017.
[11] Mostafa Dehghani, et al. “Universal Transformers” ICLR 2019.
[12] Emilio Parisotto, et al. “Stabilizing Transformers for Reinforcement Learning” arXiv:1910.06764 (2019).
[13] Rae et al. “Compressive Transformers for Long-Range Sequence Modelling.” 2019.
[14] Press et al. “Train Short, Test Long: Attention With Linear Biases Enables Input Length Extrapolation.” ICLR 2022.
[15] Wu, et al. “DA-Transformer: Distance Aware Transformer” 2021.
[16] Elabyad et al. “Depth-Adaptive Transformer.” ICLR 2020.
[17] Schuster et al. “Confident Adaptive Language Modeling” 2022.
[18] Qiu et al. “Blockwise self-attention for long document understanding” 2019
[19] Roy et al. “Efficient Content-Based Sparse Attention with Routing Transformers.” 2021.
[20] Ainslie et al. “ETC: Encoding Long and Structured Inputs in Transformers.” EMNLP 2019.
[21] Beltagy et al. “Longformer: The long-document transformer.” 2020.
[22] Zaheer et al. “Big Bird: Transformers for Longer Sequences.” 2020.
[23] Wang et al. “Linformer: Self-Attention with Linear Complexity.” arXiv preprint arXiv:2006.04768 (2020).
[24] Tay et al. 2020 “Sparse Sinkhorn Attention.” ICML 2020.
[25] Peng et al. “Random Feature Attention.” ICLR 2021.
[26] Choromanski et al. “Rethinking Attention with Performers.” ICLR 2021.
[27] Khandelwal et al. “Generalization through memorization: Nearest neighbor language models.” ICLR 2020.
[28] Yogatama et al. “Adaptive semiparametric language models.” ACL 2021.
[29] Wu et al. “Memorizing Transformers.” ICLR 2022.
[30] Su et al. “Roformer: Enhanced transformer with rotary position embedding.” arXiv preprint arXiv:2104.09864 (2021).
[31] Shaw et al. “Self-attention with relative position representations.” arXiv preprint arXiv:1803.02155 (2018).
[32] Tay et al. “Efficient Transformers: A Survey." ACM Computing Surveys 55.6 (2022): 1-28.
[33] Chen et al., “Decision Transformer: Reinforcement Learning via Sequence Modeling” arXiv preprint arXiv:2106.01345 (2021).